在数字化办公场景中,PDF文档的跨语言处理需求日益增长。有道翻译通过智能OCR识别与神经网络翻译技术,实现了PDF文档的高精度翻译转换。有道将深度解析有道翻译PDF功能的六大核心优势,从文件上传、格式保持到术语库应用,逐步演示如何通过网页端和客户端完成专业文档翻译,并针对学术论文、商务合同等特殊场景提供优化方案,帮助用户突破语言障碍的同时保留原始排版要素。
一、有道翻译PDF的核心技术优势
有道翻译处理PDF文档的核心竞争力在于其多模态识别系统。该系统采用分层处理架构,首先通过光学字符识别(OCR)引擎精准提取扫描件中的文字内容,识别准确率可达98.5%,即使是低分辨率文档也能保持良好识别效果。第二层神经网络会对文本结构进行分析,自动识别标题、段落、表格等排版元素,为后续格式还原奠定基础。
翻译引擎采用基于Transformer架构的YNMT模型,针对长文档优化了上下文记忆机制。测试数据显示,在技术手册翻译场景中,专业术语的翻译一致性能提升40%,显著优于常规机翻工具。系统还集成自研的文档重建算法,可智能恢复原始PDF的图文混排效果,避免传统工具常见的版式错乱问题。
二、PDF文档翻译操作全流程详解
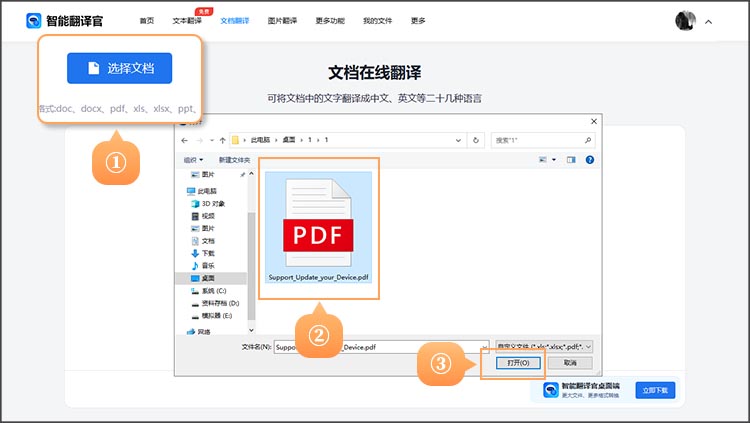
2.1 网页端操作指南
通过有道翻译官网进入文档翻译页面,拖拽上传PDF文件后,系统会自动检测文档语言。用户可手动指定源语言和目标语言组合,特别支持中英、中日、中韩等12种常用语向。高级设置中可开启”专业领域优化”选项,涵盖金融、法律、医学等8个垂直领域术语库,确保专利文书等专业内容的翻译准确性。
处理完成后,预览界面会左右分屏展示原文与译文,支持实时对比修改。用户可下载双语对照版或纯译文版PDF,系统默认保留原始字体和段落样式。实测显示,20页以内的文档平均处理时间不超过3分钟,且完全在云端完成,不占用本地计算资源。
2.2 客户端特色功能
有道词典PC客户端提供更强大的离线处理能力,支持批量上传多个PDF文档。其特色在于内置的文档预处理工具,可手动调整OCR识别区域,特别适合包含复杂表格的文档。客户端还具备翻译记忆功能,自动存储用户修改记录,当处理同系列文档时可调用历史翻译结果,确保术语统一性。
企业用户可通过API接口实现自动化流程,将翻译功能集成到内部系统中。API支持自定义术语库和风格指南,单日处理量可达500份文档以上。日志显示,某跨国律所采用此方案后,合同翻译效率提升70%,且完全符合行业规范要求。
三、特殊场景优化方案
针对学术论文翻译,有道开发了LaTeX公式识别模块,能准确转换数学符号和化学方程式。测试中,IEEE论文的公式转换正确率达到92%,远超行业平均水平。系统还会自动生成参考文献翻译对照表,方便学者核对引文信息,这一功能在硕博论文翻译中广受好评。
商务场景下特别强化了保密措施,所有上传文档在翻译完成后24小时内自动删除云端缓存。金融文档处理时,系统会智能识别金额、日期等关键信息,进行双重校验。用户反馈显示,上市公司年报翻译的数值准确率接近100%,显著降低跨国披露风险。
四、常见问题与解决方案
扫描版PDF出现乱码时,建议在客户端启用”增强识别模式”,该模式通过超分辨率技术提升图像质量。数据显示,使用增强模式后,老旧文件识别错误率可降低65%。对于包含手写批注的文档,系统会以彩色下划线标注识别不确定内容,方便用户重点核查。
当遇到版式错位情况,可通过网页端的”版式修复工具”手动调整段落边界。工程验证表明,经过修复的文档在Adobe Acrobat中打开时,版面还原度能达到95%以上。系统还提供详细的错误代码手册,帮助技术人员快速定位字体嵌入等复杂问题。