Mac有道翻译桌面版整合划词、截图、文档、音视频与 AI 对话,专为 Apple Silicon 深度优化,几分钟安装,让跨语言阅读与写作从此毫无门槛。
免费下载 macOS 版六大能力矩阵覆盖阅读、写作、会议、学习全场景,一次安装,随取随用。

任意 App 中鼠标划词或悬停即时出译,支持中英日韩法德西俄等 109 种语言互译。
快捷键框选屏幕任意区域,本地 OCR 识别 + AI 翻译一步完成,图像文字也能读懂。
Word / PDF / PPT / Excel 保留原排版与图文样式,术语库自动应用,长文档批处理。
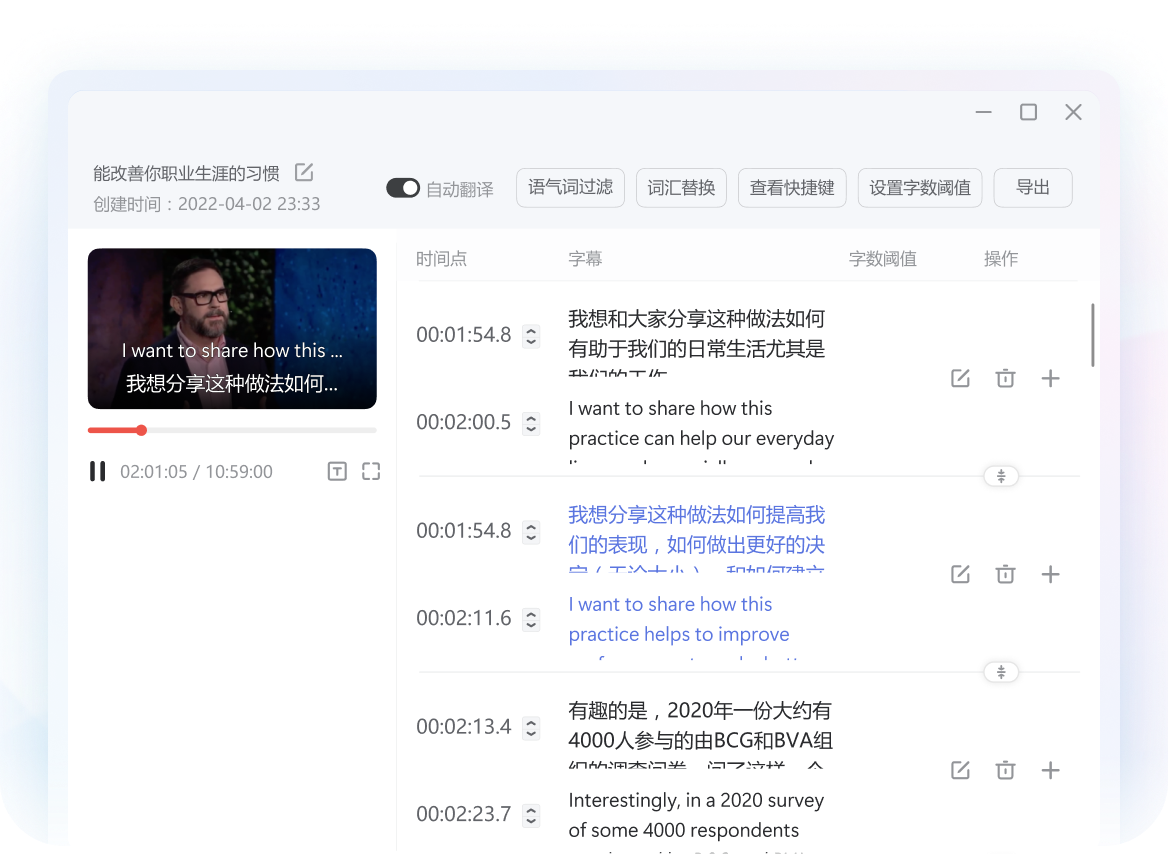
MP3 / MP4 / MOV 等常见格式在线转写,一键生成中英字幕并导出 SRT / VTT。
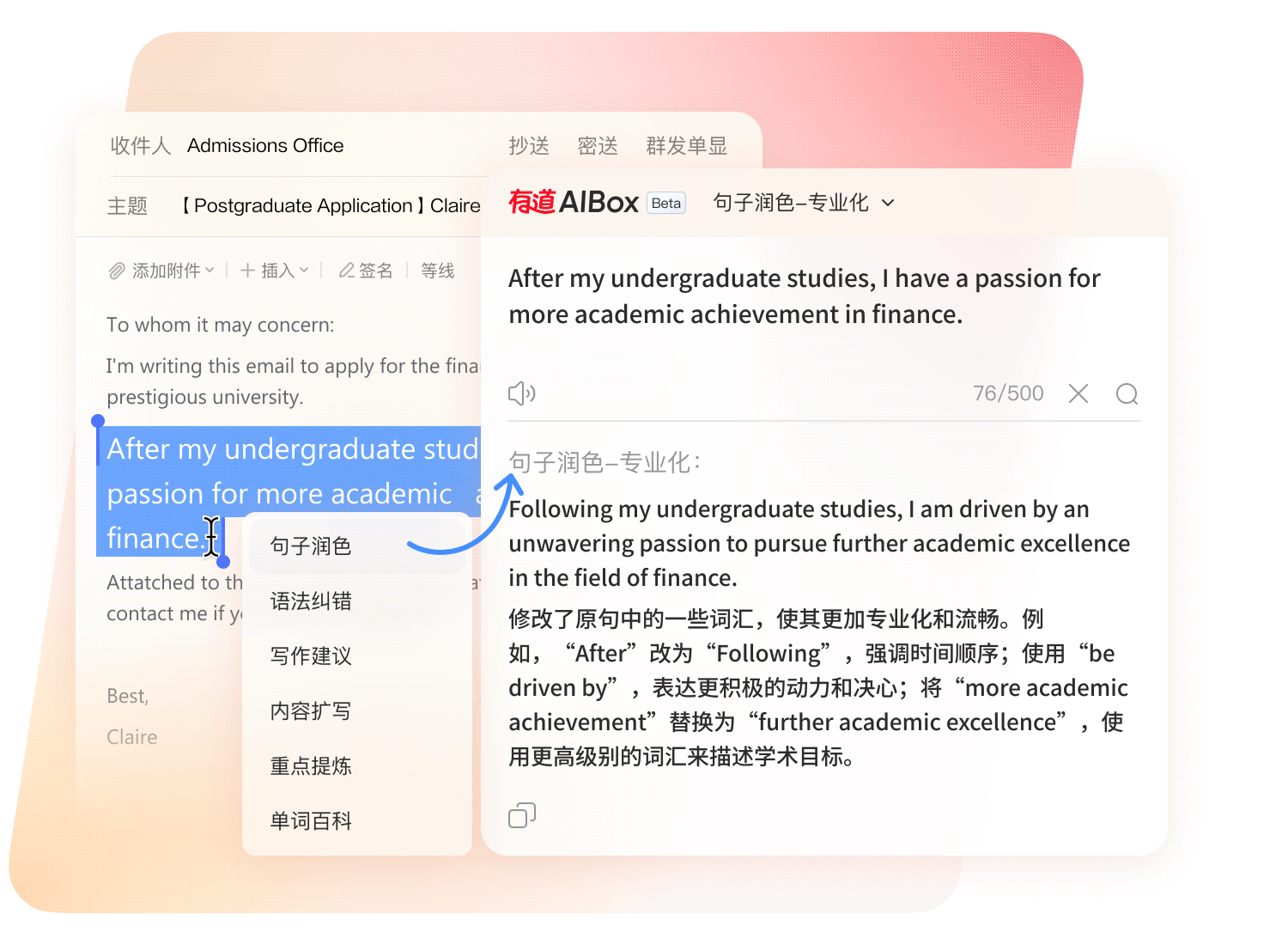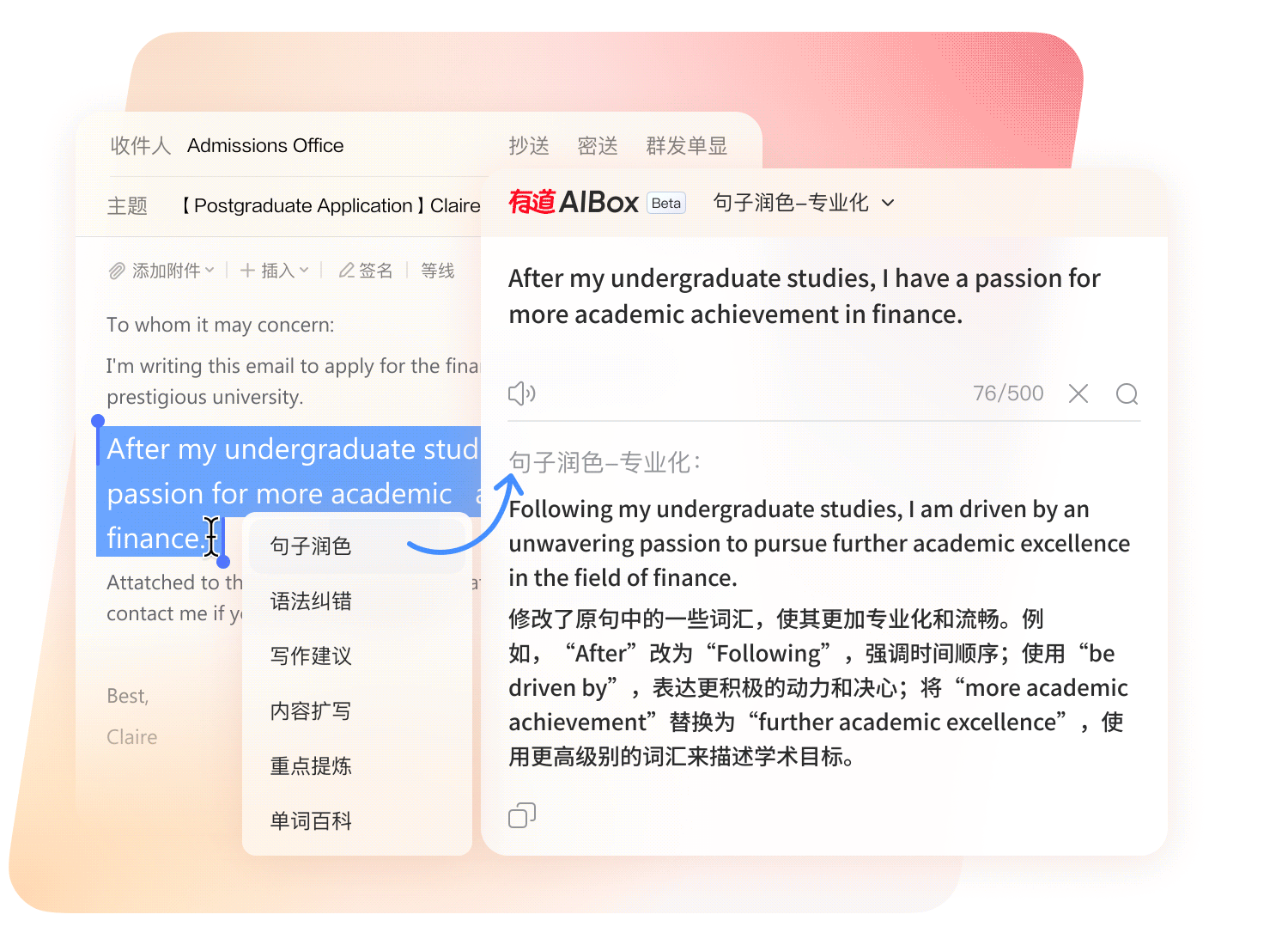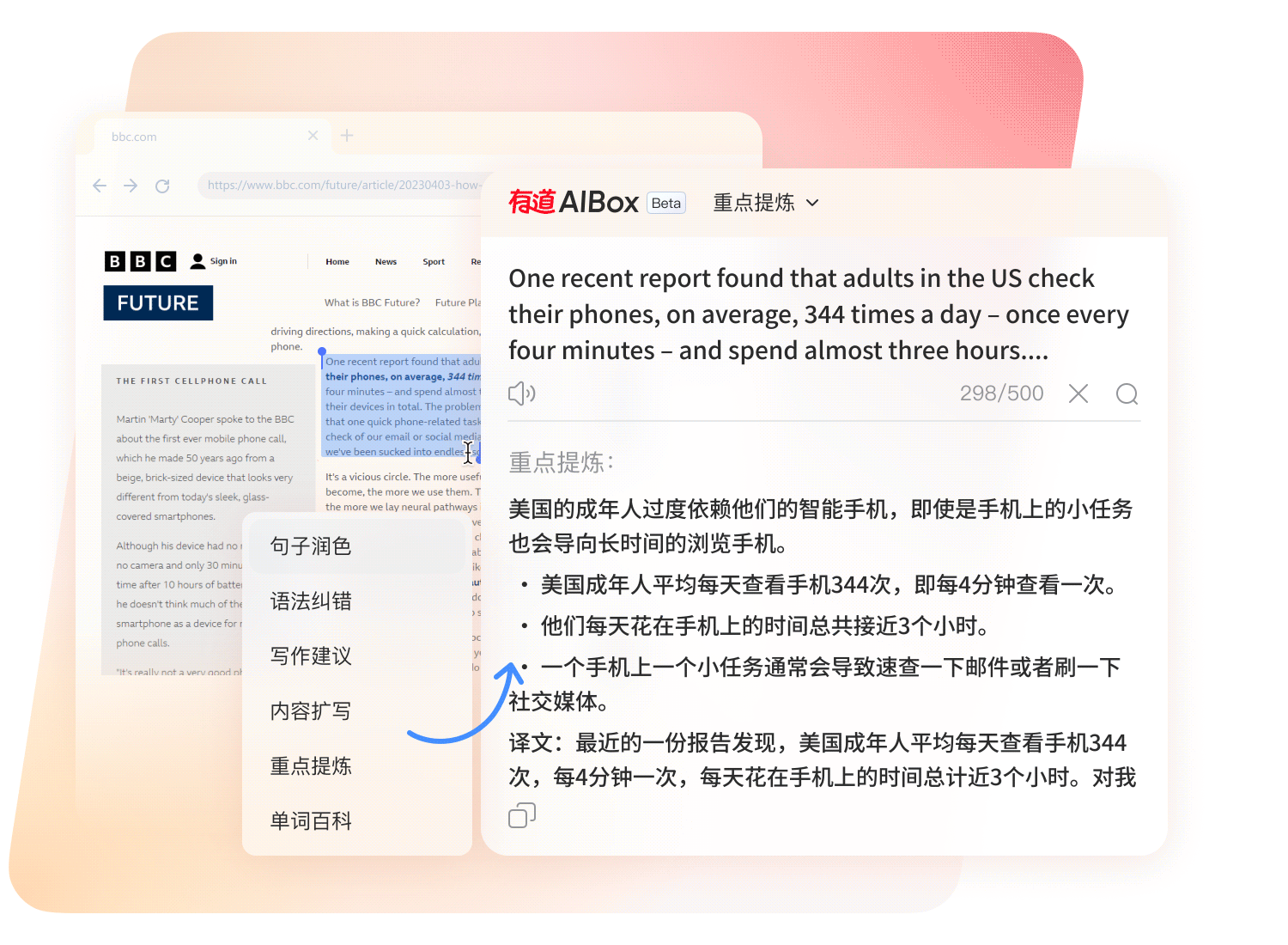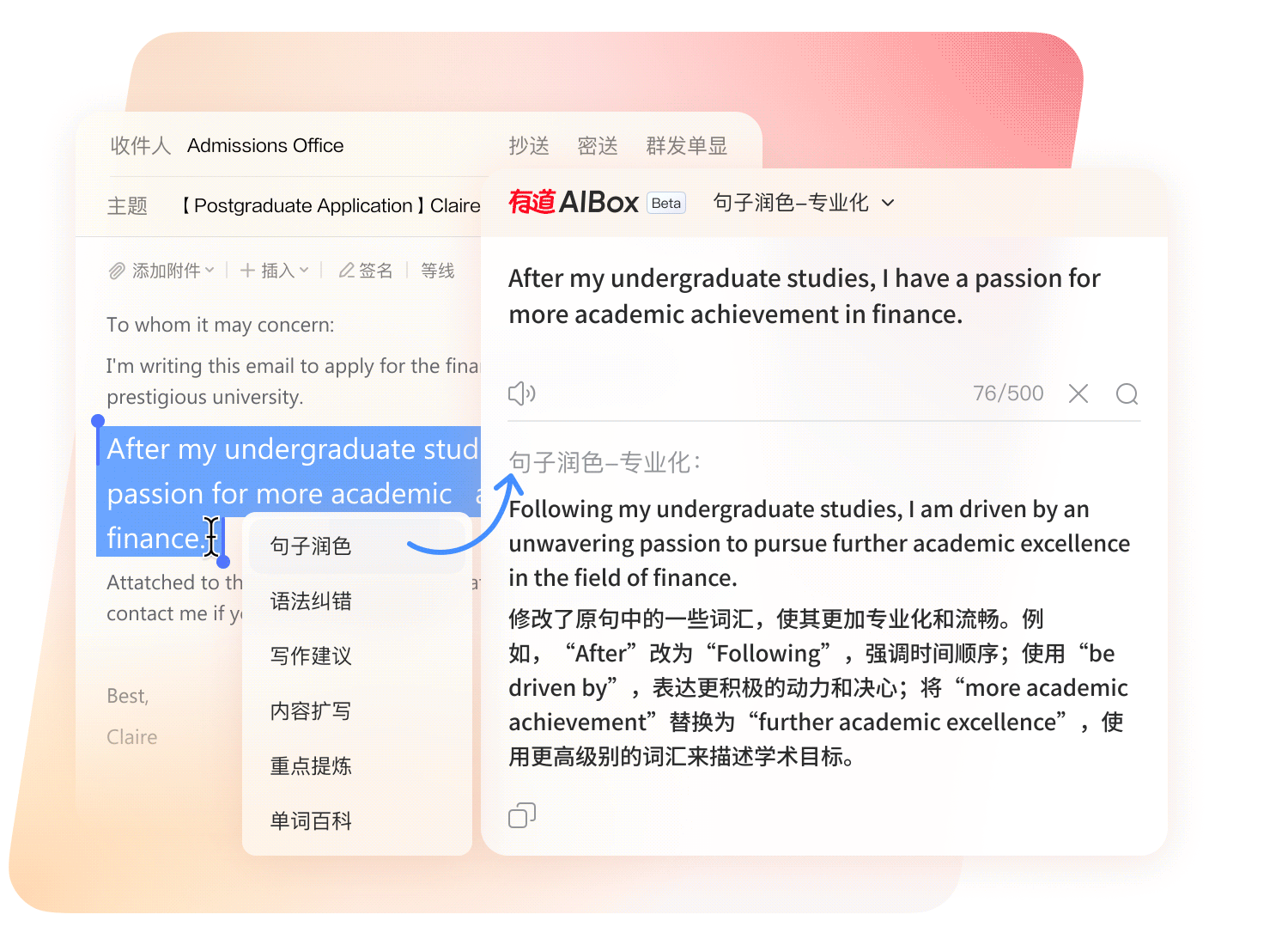
划词呼出 AI 助手,翻译、改写、总结、扩写、语法纠错一站式处理。
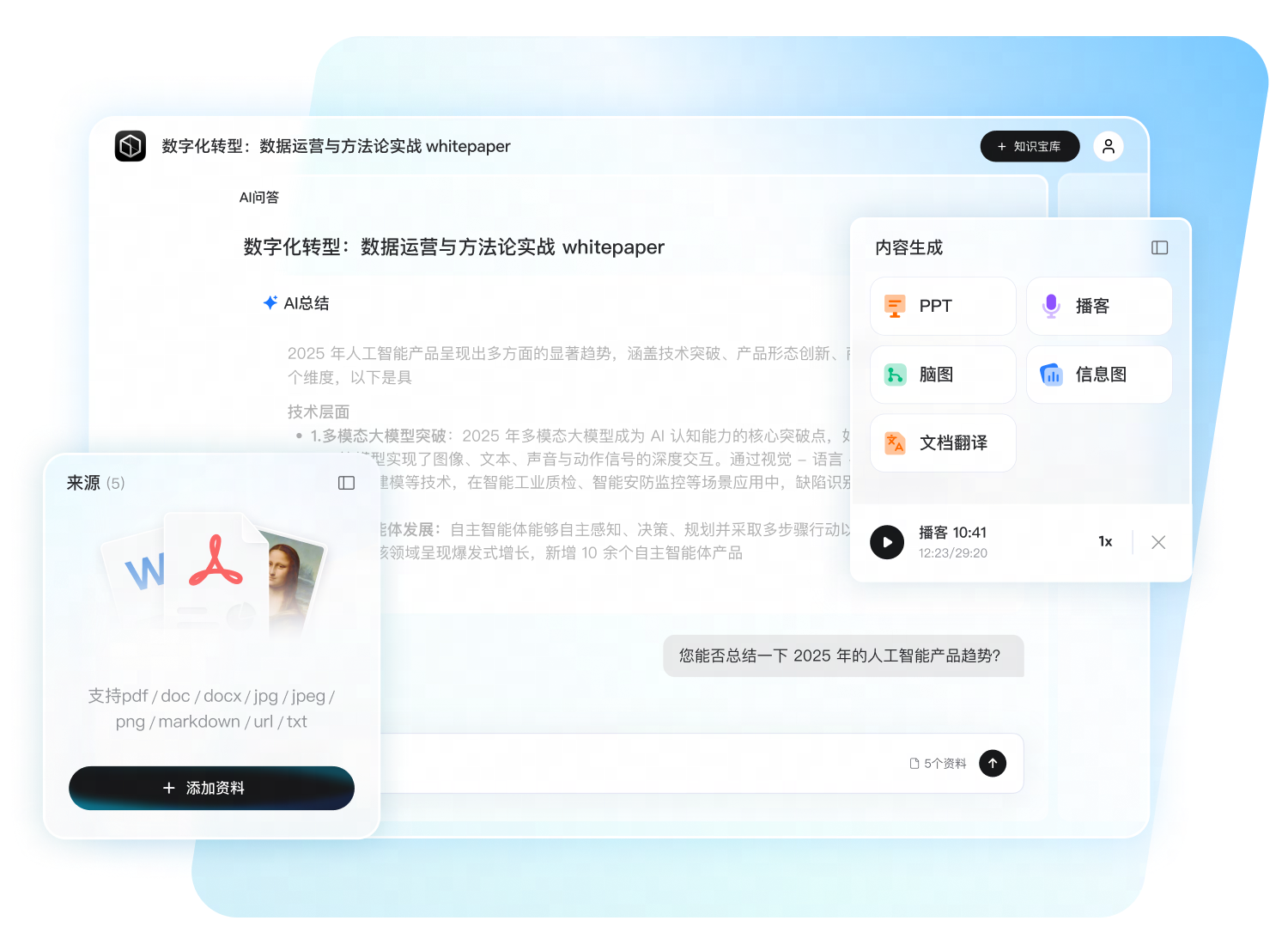
行业术语、专有名词一次录入,跨设备同步,保证长期项目译文一致性。
从个人到企业,从桌面到移动,我们为不同角色提供合适的翻译方案。

Mac / Windows / Linux 三端原生体验,全局快捷键、离线词典、AI 处理全部本地触发。

iOS 与 Android 双端,作文批改、拍照翻译、口语练习覆盖学习全流程。

Chrome / Edge / Brave 网页翻译,Manifest V3 架构,占用低不打扰阅读。

私有化术语库、协同翻译、安全审计,为跨国团队提供合规的语言服务。
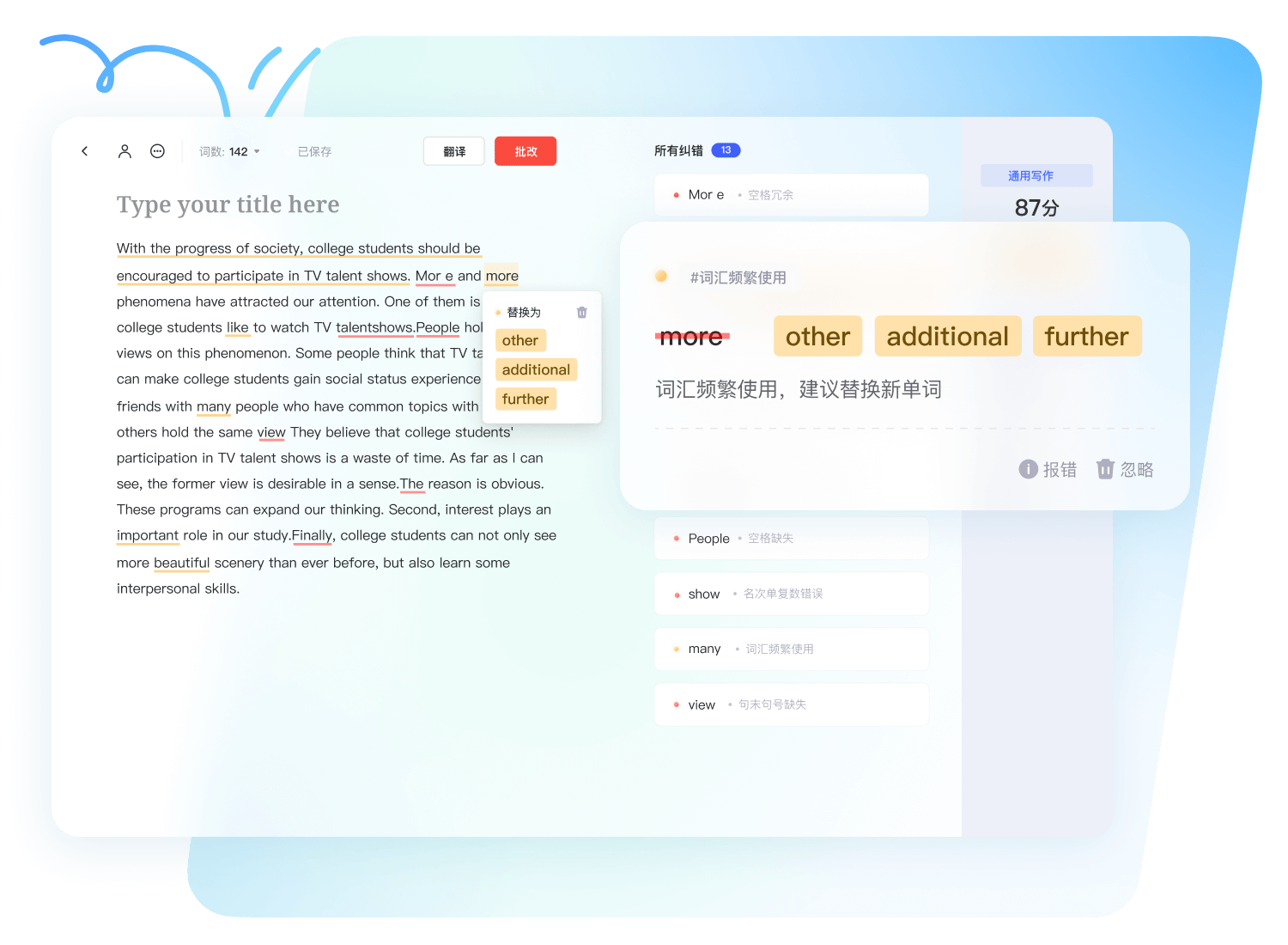
解锁大模型翻译、长文档不限量、优先算力通道与更多 AI 写作能力。

专业译员 24 小时接单,法律、专利、财报等重要文档人工兜底。
Mac有道翻译团队专注于跨语言智能工具十余年,将自研翻译大模型、行业术语库与人工译审流程融合为一套顺手的桌面产品。
我们相信,好的翻译工具不该让你打断思考。因此我们把复杂的模型和字典能力藏在快捷键背后——你只需要划词、截图或拖入文档,剩下的交给 AI。
覆盖桌面与浏览器,一次登录多端账户与术语同步。
在联系客服前,也许答案已经在这里。
是的,Mac有道翻译已针对 M 系列芯片编译原生二进制,同时兼容 Intel 芯片的 Mac 设备。
桌面版支持全局划词、截图翻译、系统级快捷键与本地术语库;网页版免安装即用,适合临时场景。
目前支持 Word (.docx)、PDF、PowerPoint (.pptx)、Excel (.xlsx)、Markdown 与纯文本,翻译后保留原排版。
免费版可满足日常划词与短文翻译;会员解锁大模型引擎、超长文档、音视频转译不限时长等高阶能力。
翻译内容仅用于返回结果,不会用于模型训练或商业用途,详见隐私政策。