有道翻译近日宣布,已在业内率先建成并应用全新的「云-边-端」协同AI推理架构,旨在从根本上解决用户在翻译过程中遇到的网络延迟、高成本和隐私安全等核心痛点。这一创新架构通过智能调度系统,将云端强大的计算能力、边缘节点的低延迟优势与终端设备的即时响应能力有机结合,为亿万用户带来了更快速、更流畅、更安全的翻译体验,树立了AI翻译服务的新标杆。
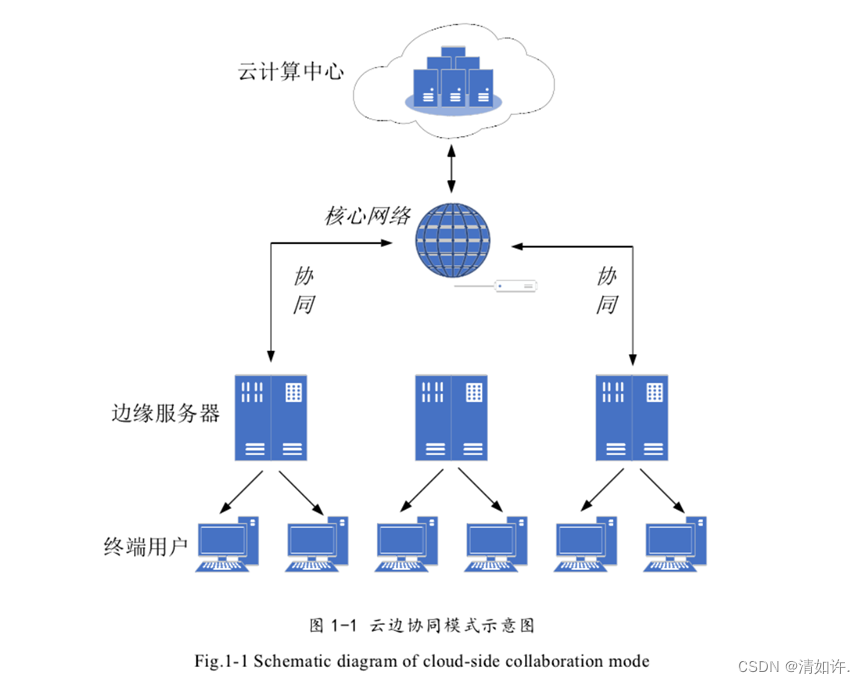
作为一家深耕语言科技多年的公司,网易有道始终致力于通过技术创新提升用户体验。传统的AI翻译服务主要依赖云端强大的服务器进行计算,虽然能支持复杂的深度学习模型,但其固有的网络延迟和数据传输成本成为体验提升的瓶颈。而纯粹的端侧(On-device)方案虽能实现离线使用和更好的隐私保护,却受限于手机等设备的算力和存储,难以运行最先进、最高精度的翻译模型。面对这一行业共性难题,有道技术团队前瞻性地提出了「云-边-端」协同的解决方案,将AI推理能力泛化到从云到端的完整路径上,实现了资源的最优配置和用户体验的极致优化。
传统AI翻译架构的瓶颈:为何变革势在必行?
在探讨有道这项创新架构之前,我们首先需要理解,为什么传统的AI翻译架构亟需一场革新?长久以来,AI翻译模型的部署主要存在两种主流模式:纯云端推理和纯端侧推理,但这两种模式都存在着难以调和的矛盾。
云端推理的“远水难解近渴”
云端部署模式,即将用户的翻译请求发送到远程数据中心的强大服务器上进行处理。其优势在于能够部署规模庞大、结构复杂的神经网络翻译(NMT)模型,从而提供非常高的翻译质量。然而,它的弊端也同样明显。首先是网络延迟,用户的请求需要经历“设备 -> 运营商网络 -> 云服务器”的漫长旅程,来回往返的时间消耗,使得实时翻译(如语音同传、AR翻译)的体验大打折扣。其次,海量用户的请求意味着巨大的服务器和带宽成本,这对于服务提供商是沉重的负担。最后,用户数据需要上传至云端,也引发了部分用户对个人隐私安全的担忧。
端侧推理的“心有余而力不足”
为了解决云端模式的问题,端侧推理应运而生。它将轻量化的AI模型直接部署在用户的手机或智能硬件上,实现了“即发即算”,完美解决了网络延迟和离线使用的问题,并且数据保留在本地,隐私性极佳。但这又带来了新的挑战。受限于终端设备有限的计算能力、内存和功耗,端侧模型必须经过大幅压缩和简化,这往往以牺牲一定的翻译精度为代价。此外,模型的更新和迭代也较为困难,无法像云端一样快速部署最新的科研成果。简而言之,用户不得不在“速度”和“精度”之间做出妥协。
破局之道:详解有道「云-边-端」协同AI推理架构
面对上述困境,有道翻译没有选择非此即彼的单一路线,而是开创性地构建了「云-边-端」三位一体的协同AI推理架构。这个架构的核心思想是:让最合适的计算发生在最合适的位置。它不再将三者割裂看待,而是将其视为一个统一、弹性的算力资源池,通过一个“智能大脑”进行动态、实时的调度。
各司其职:云、边、端的三位一体
在这个全新的体系中,云、边、端不再是孤立的节点,而是协同作战的团队成员,各自扮演着不可或缺的角色。
| 计算层级 | 核心角色与功能 | 解决的关键问题 |
|---|---|---|
| 云 (Cloud) | 最终算力保障与模型训练中心。部署最大、最全、最强的超大规模翻译模型。负责处理最复杂的翻译任务、长文本翻译,并作为整个系统的模型训练和迭代基地。 | 保证翻译质量的上限,处理端、边无法应对的复杂请求。 |
| 边 (Edge) | 区域性低延迟计算节点。在靠近用户的网络边缘(如运营商机房)部署中等规模的高性能模型。它像一个前置缓存和计算哨所,极大缩短了网络传输距离。 | 解决云端推理的“最后一公里”延迟问题,显著提升实时翻译的响应速度。 |
| 端 (End) | 即时响应与隐私保护单元。在用户设备上部署轻量级、高效率的离线翻译模型。负责处理简单的、高频的、或在无网络环境下的翻译请求。 | 实现零延迟、离线可用性,并从根本上保障用户数据的隐私安全。 |
智能大脑:自适应推理调度系统如何工作?
这个架构的精髓,在于其背后的自适应推理调度系统。它就像一个经验丰富的智能交通指挥官,每一条翻译请求到来时,它会基于一系列实时参数,在毫秒之间做出决策:这次请求应该发往云、边,还是在端上直接完成?
这个决策过程主要考量以下几个维度:
- 网络状态:当前用户的网络是5G、Wi-Fi,还是信号不佳的4G,甚至是离线状态?网络质量好,可以考虑边或云;网络差或无网络,则必须由端处理。
- 任务复杂度:用户输入的是一个单词、一个短句,还是一篇长文档?简单的任务可以在端上秒速完成,复杂的任务则需要云端强大的模型来保证质量。
- 设备状态:用户手机的电量是否充足?设备性能如何?在低电量或设备性能较弱时,系统会倾向于将计算任务卸载到边或云,以节省本地资源。
- 服务成本与负载:系统会综合评估云端和边缘节点的实时负载情况,动态调整流量分配,在保证用户体验的前提下,实现整体计算成本的最优化。
正是这个智能调度系统,将原本固化的计算模式变得灵活、高效、自适应,从而实现了“1+1+1>3”的协同效应。
全面赋能:新架构为用户体验带来哪些革命性提升?
理论的先进最终要落实到用户的实际体验上。有道「云-边-端」协同AI推理架构的落地,为翻译服务带来了看得见、摸得着的革命性提升。
极致速度:响应延迟降低高达98%
对于用户而言,最直观的感受就是“快”。通过将大量计算前置到边缘节点和用户终端,新架构成功绕开了传统云服务的漫长链路。根据有道内部测试数据,在同等网络环境下,新架构下的平均翻译响应延迟相比传统纯云端模式降低了90%以上,在特定场景下(如边缘计算命中),延迟甚至可以降低惊人的98%。这意味着用户在进行语音对话翻译或AR实时翻译时,几乎感受不到任何卡顿,真正实现了“所说即所译”。
无缝体验:实现真正的离在线无感切换
“翻译App一进地铁就失灵”,这是许多用户都曾遇到的尴尬。新架构彻底解决了这个问题。智能调度系统能够实时感知网络变化,当用户从Wi-Fi环境进入无网络环境时,系统会自动、平滑地将翻译任务从云或边切换至端侧模型,整个过程用户毫无感知。这种离在线的无缝切换,保证了用户在任何时间、任何地点都能获得稳定可靠的翻译服务,极大提升了应用的普适性和可靠性。
成本优化与隐私保护:更高效、更安全的AI服务
从服务运营的角度看,新架构通过将大量计算分流至成本更低的边缘和终端,显著降低了对昂贵云端资源的依赖,实现了整体运营成本的大幅优化。而这种成本的节约,最终会转化为更普惠、更优质的服务提供给用户。同时,由于大量数据(尤其是简单、高频的查询)直接在端侧处理,无需上传云端,用户的个人数据和隐私得到了最大程度的保护,这在数据安全日益受到重视的今天,具有非凡的意义。
行业标杆:有道翻译为何能率先实现这一技术突破?
在AI翻译领域,实现「云-边-端」协同架构并非易事,它需要深厚的技术积淀和庞大的工程实践能力。有道翻译能够成为行业“第一个吃螃蟹的人”,绝非偶然。
深厚的技术积累与前瞻性布局
网易有道自研的神经网络翻译(NMT)技术一直处于世界领先水平。我们不仅拥有强大的云端超大模型研发能力,也在端侧模型的轻量化、小型化方面积累了丰富的经验。从有道词典笔等智能硬件的成功实践,到离线翻译功能的持续迭代,我们早已在“云”和“端”两极打下了坚实的基础。正是这种在两端同时具备顶尖技术实力的底蕴,让我们有能力去思考和构建将它们连接起来的“边”和“协同大脑”。
面向未来的AI基础设施建设
我们将「云-边-端」协同架构视为一项面向未来的、平台级的AI基础设施建设。这不仅仅是一个针对翻译场景的优化,更是一套可以复用到有道旗下所有AI应用的方法论和技术框架。这项工程需要对云原生技术、边缘计算、设备端AI框架以及复杂的调度算法有深刻的理解和掌控力。有道技术团队正是凭借着这种系统性的工程能力和前瞻性的战略布局,才得以攻克难关,率先建成并落地了这一行业标杆性的架构。
结语:不止于翻译,「云-边-端」开启AI应用新范式
有道翻译「云-边-端」协同AI推理架构的建成,不仅仅是一次翻译技术的升级,它更标志着AI应用服务范式的一次重要演进。它证明了,在追求更强AI模型的同时,如何通过创新的架构设计,将AI能力以更高效、更敏捷、更安全的方式交付给用户,是决定未来AI应用体验的关键。
从用户的角度看,这意味着更快的响应、更稳定的服务和更强的隐私保障。从行业的角度看,这为如何解决AI应用落地过程中的“延迟、成本、体验”不可能三角问题,提供了一个切实可行的答案。未来,我们有理由相信,这一架构思想将被更广泛地应用于在线教育、智能硬件、数字人等更多领域,开启一个由云、边、端协同驱动的,更加智能、普惠的AI新时代。而有道,将继续在这条道路上,作为坚定的探索者和引领者,不断前行。