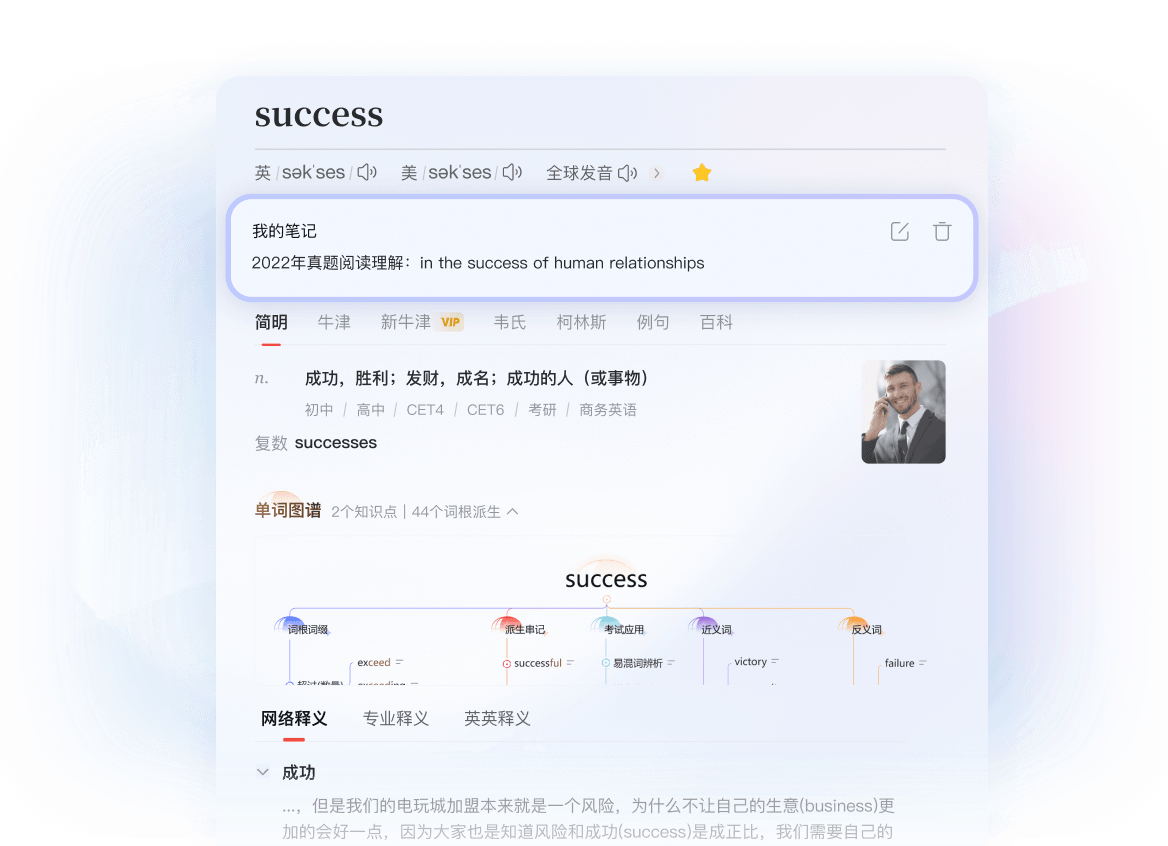
海量版权权威词库
收录《新牛津》、《韦氏》、《柯林斯》等正版词典
结合艾宾浩斯记忆曲线功能
不仅是翻译工具,更是语言学习百科
结合艾宾浩斯记忆曲线功能
不仅是翻译工具,更是语言学习百科





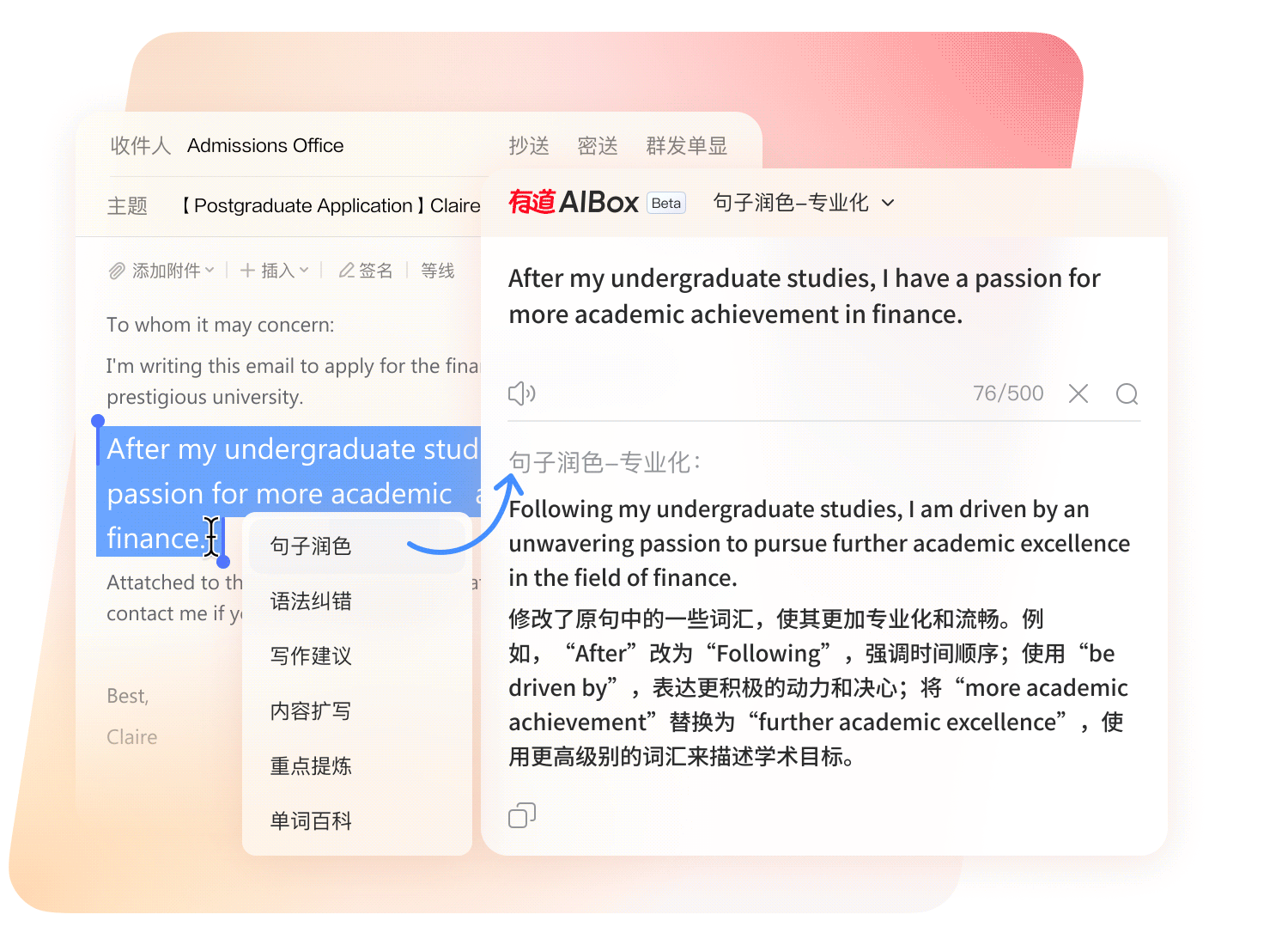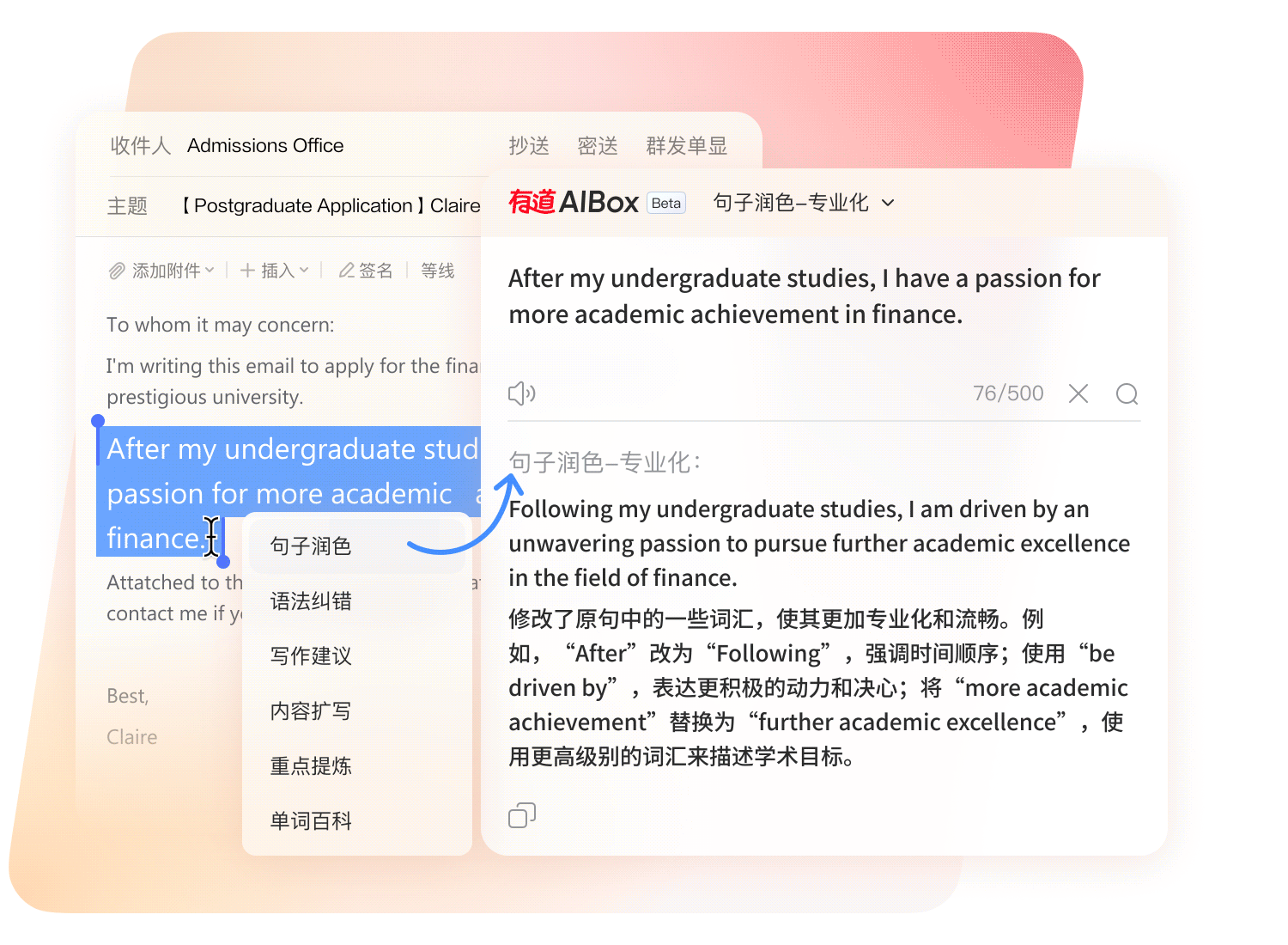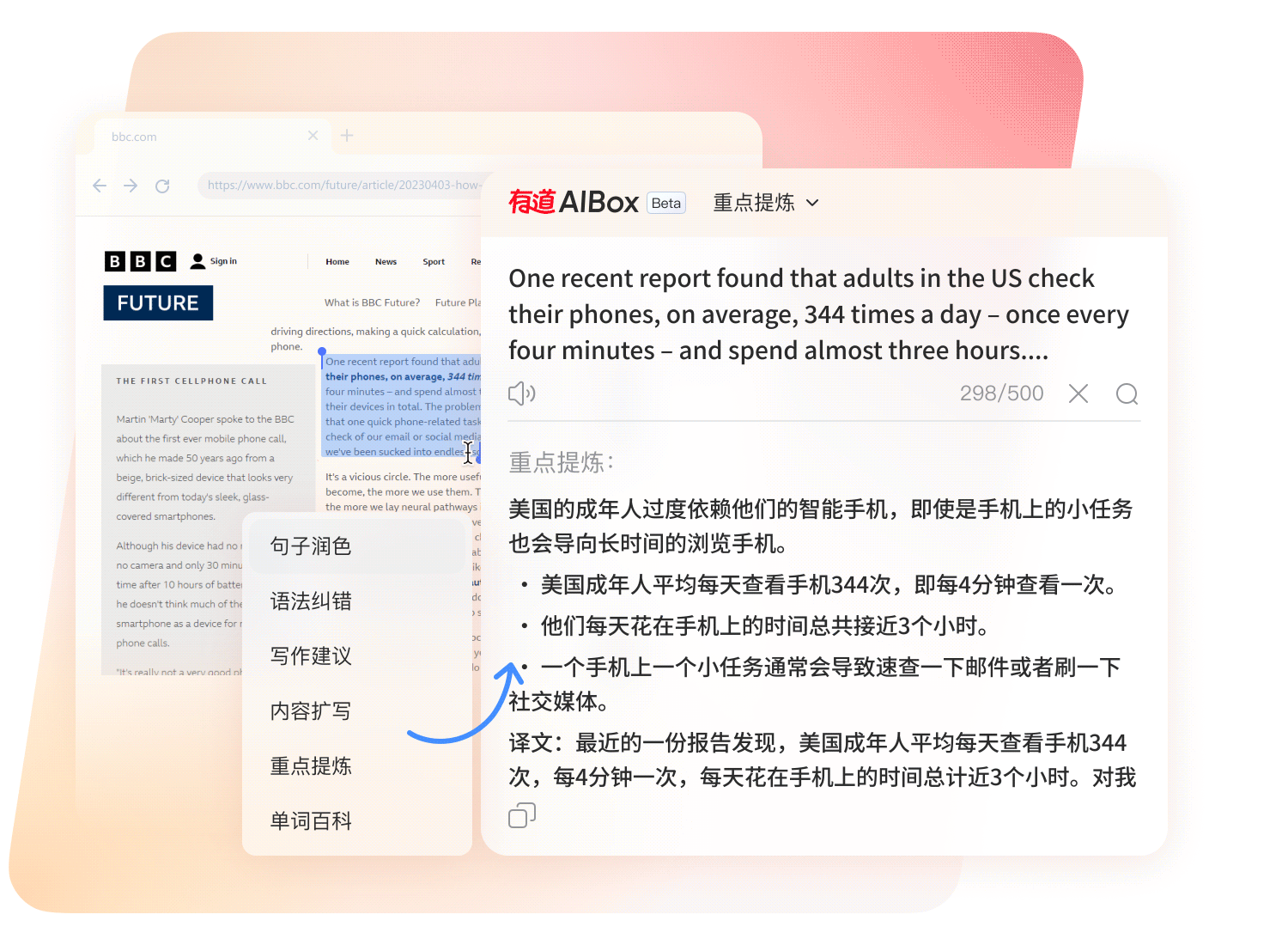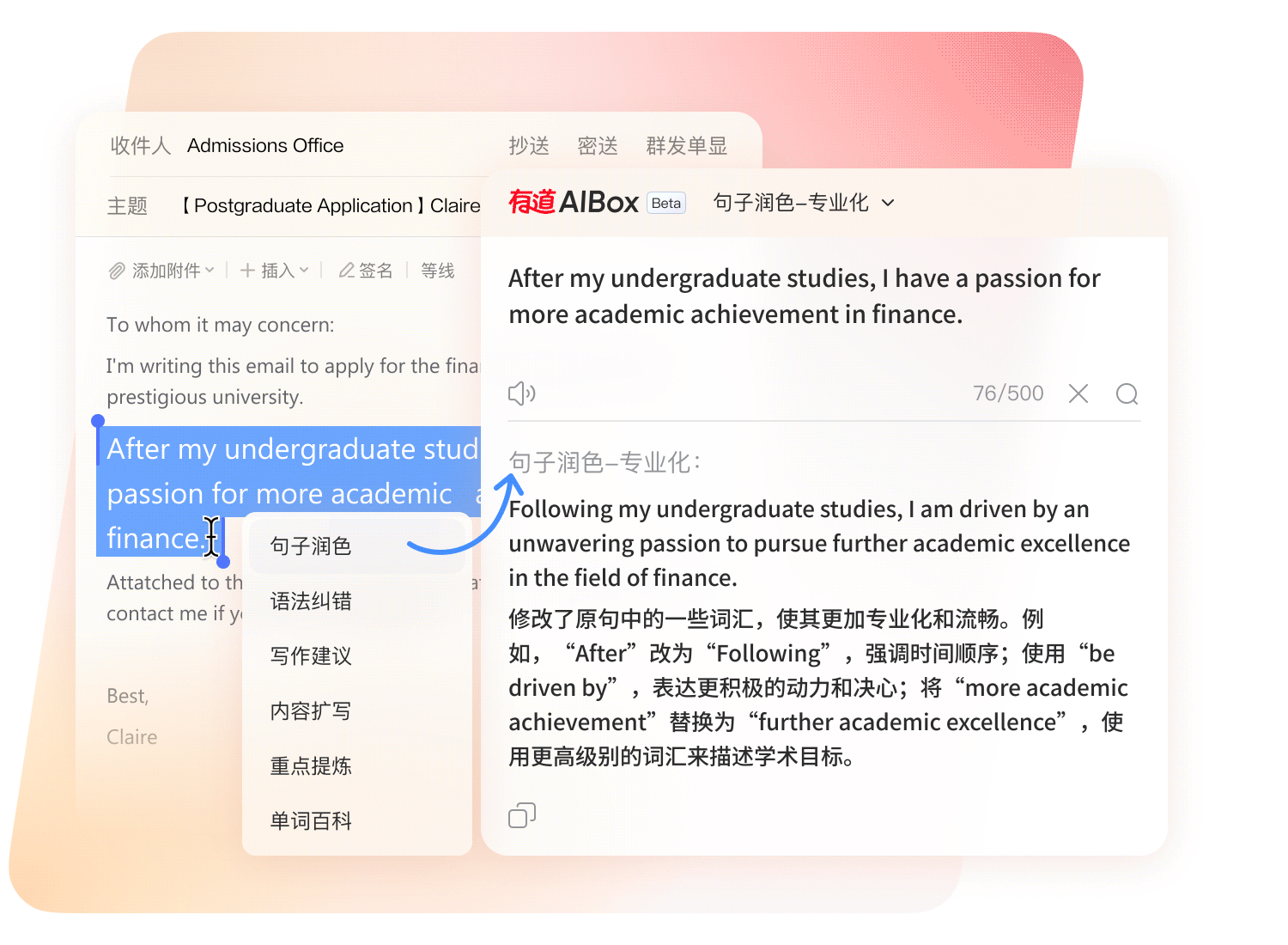
深度集成 AIGC 生成式技术,重构外语写作流程,赋予文字地道、精准与学术严谨性。
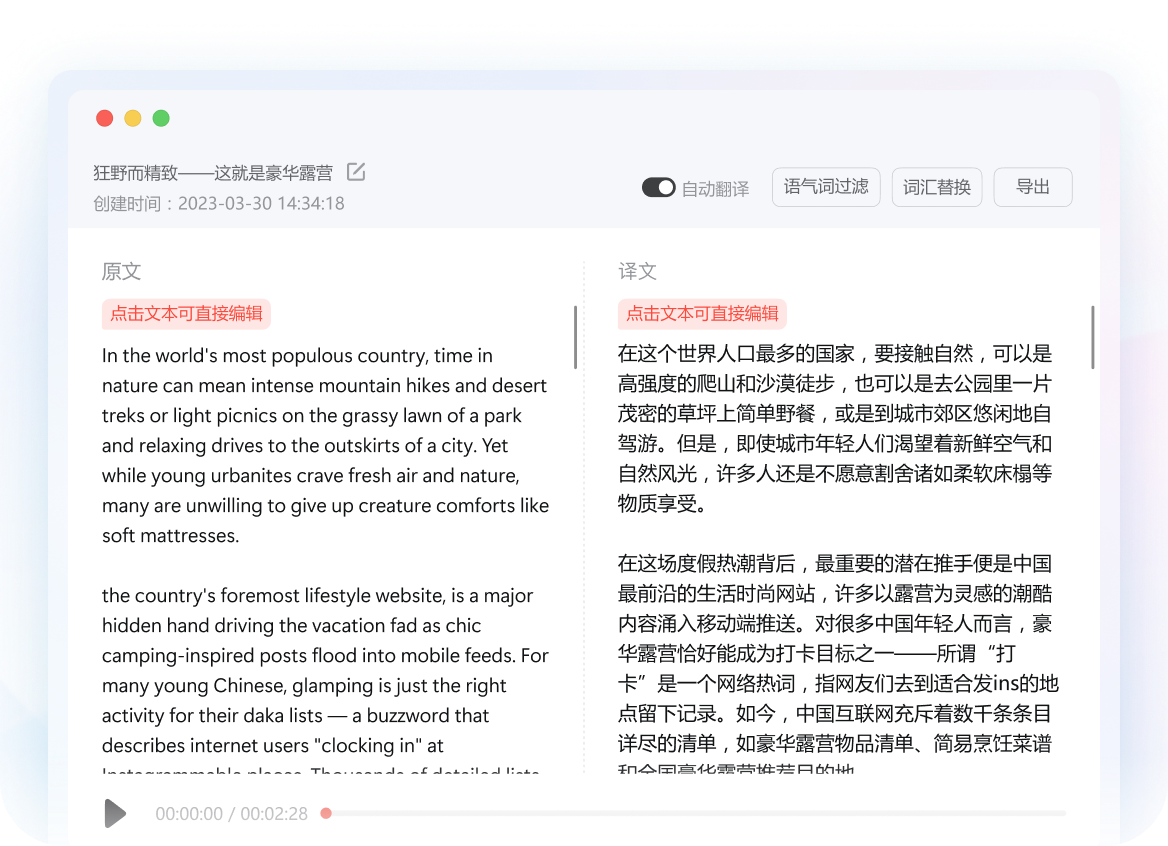
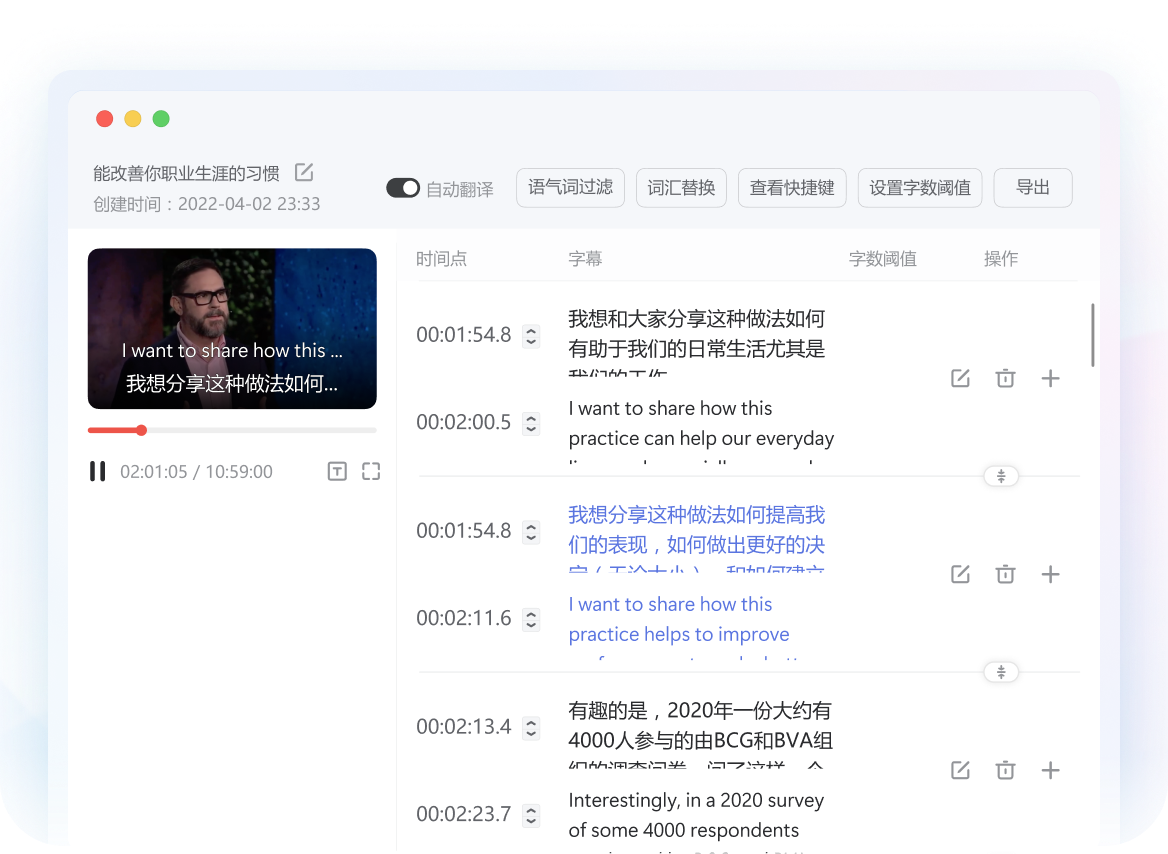
专为学术研究与跨国商务打造,全面支持 PDF / Word / PPT / Excel 等格式。
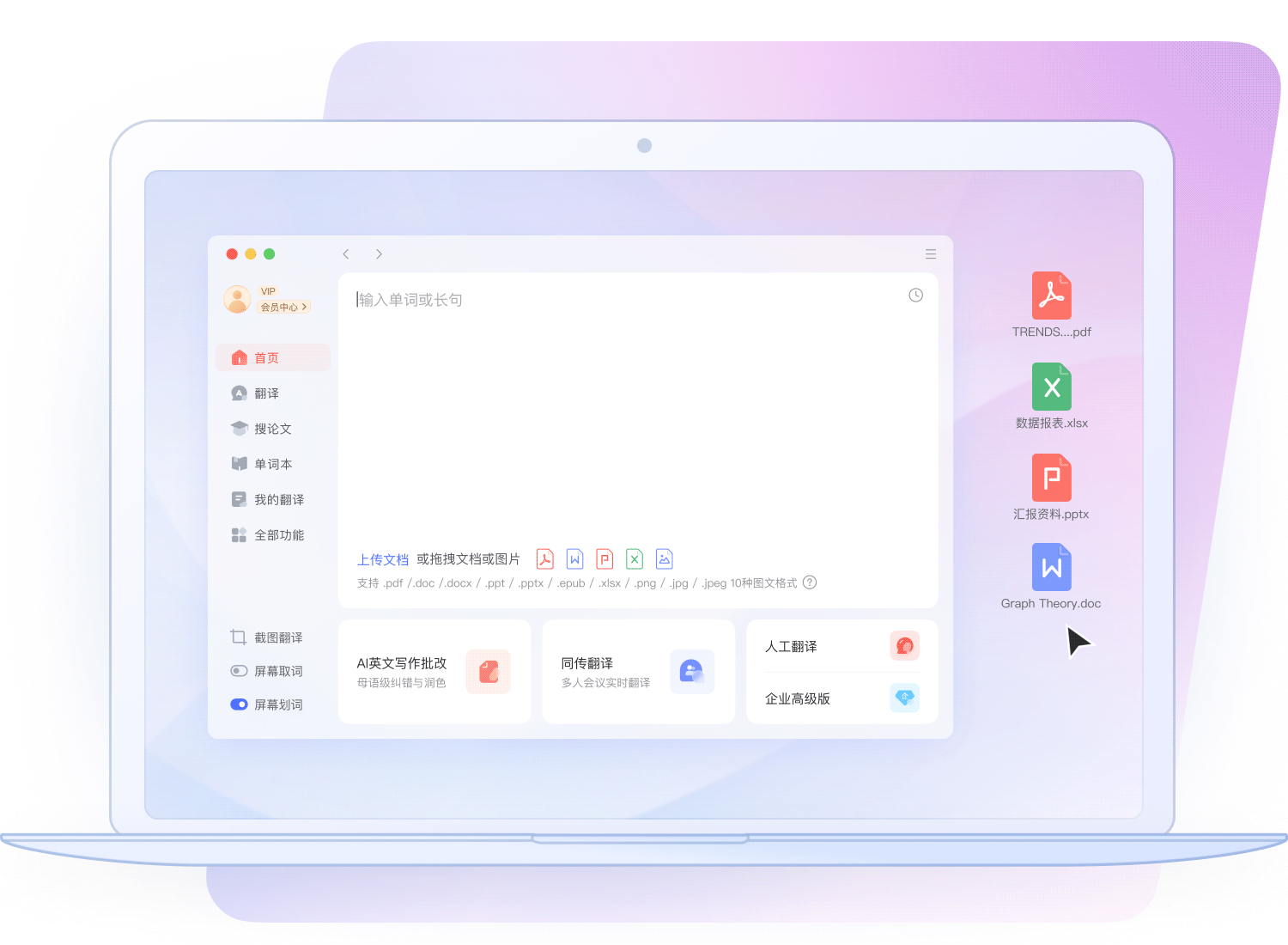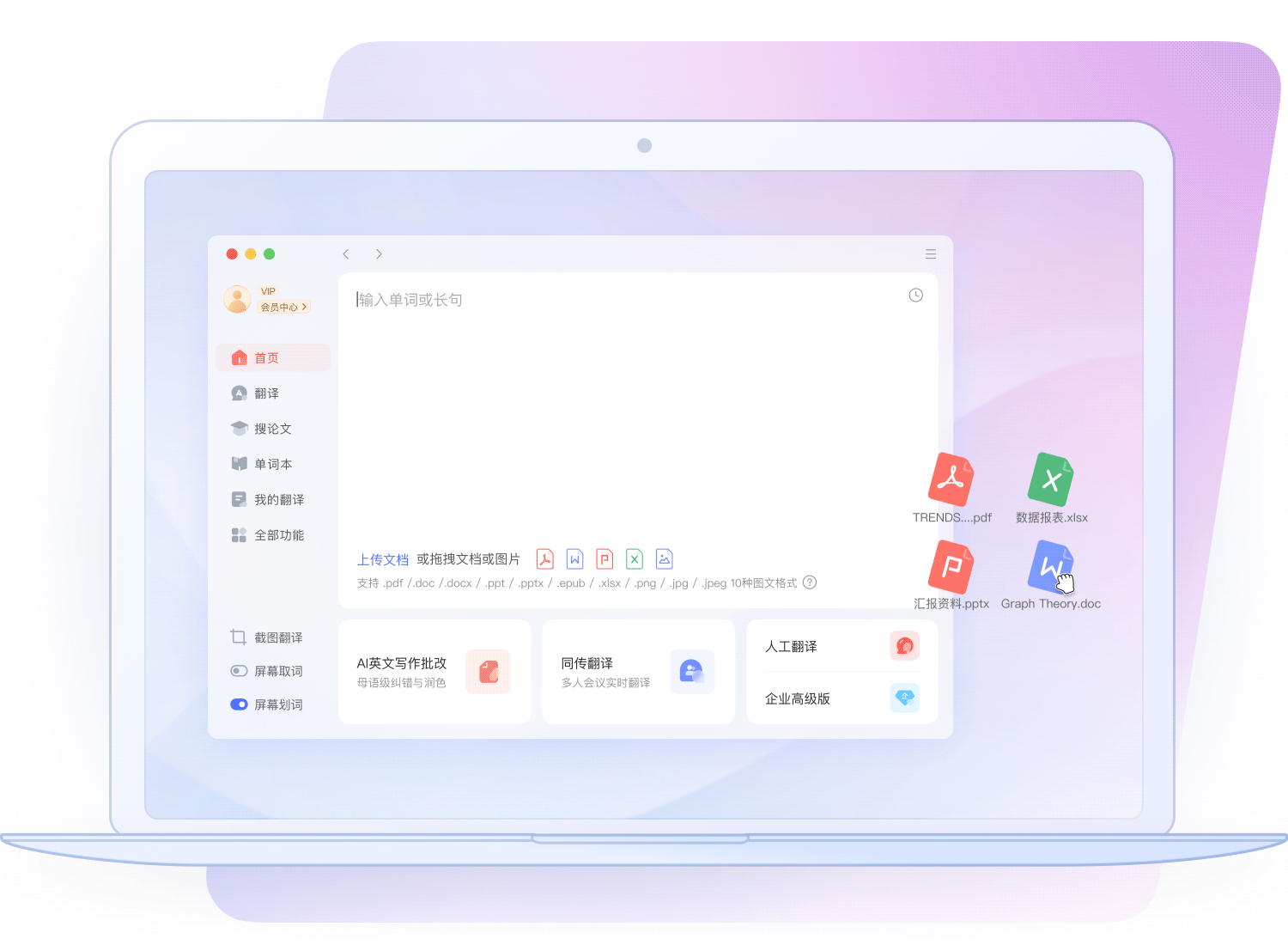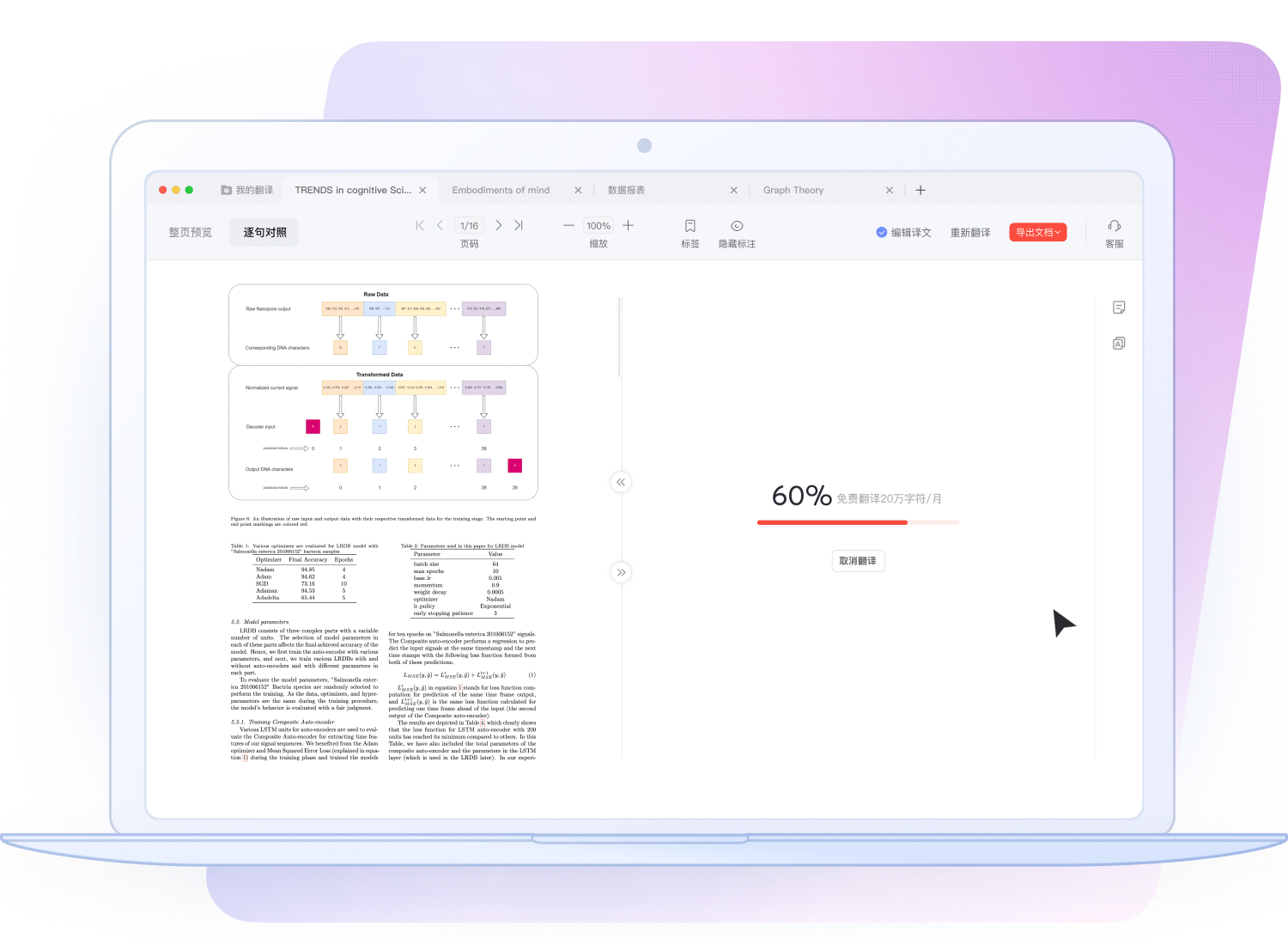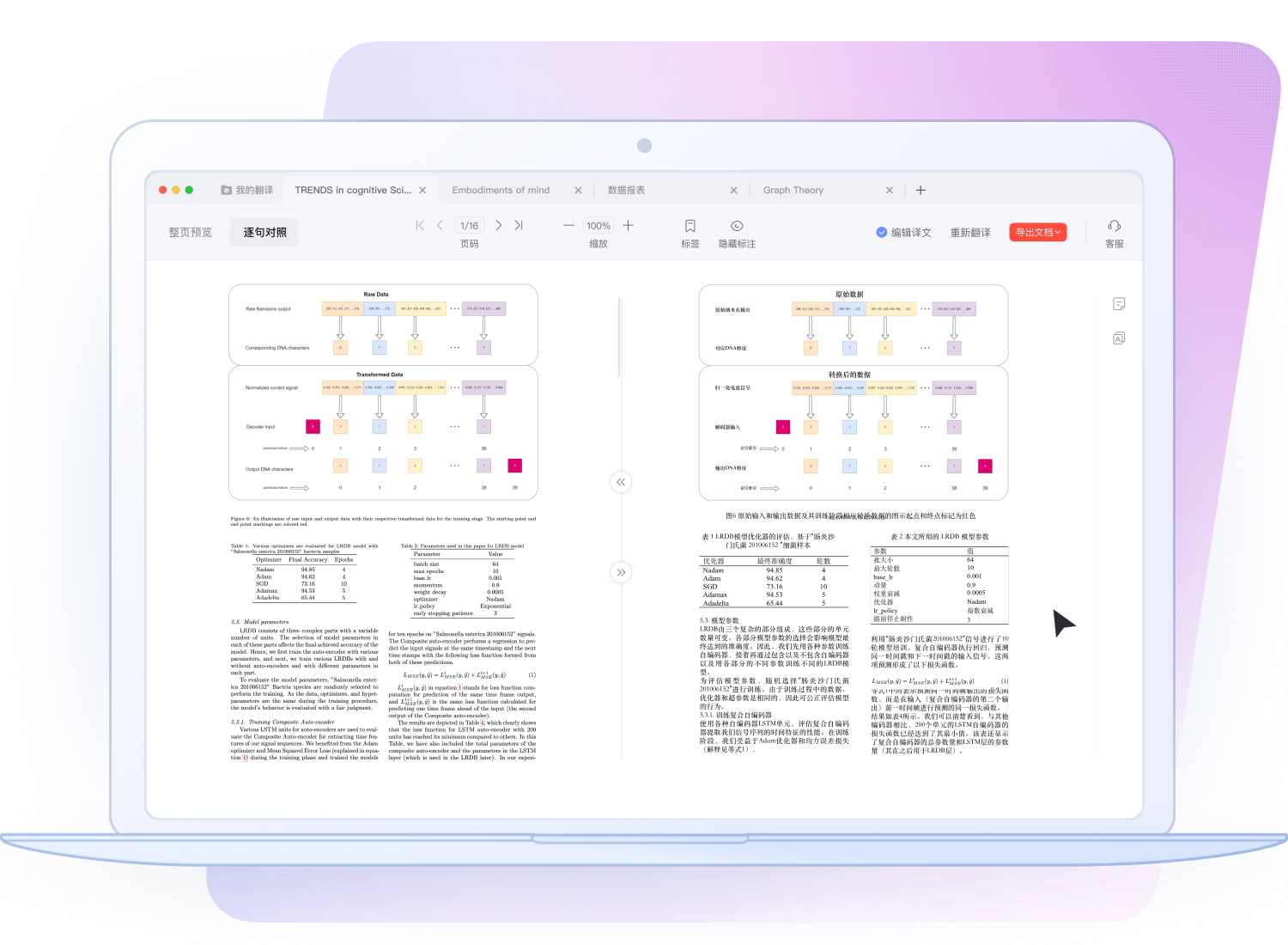
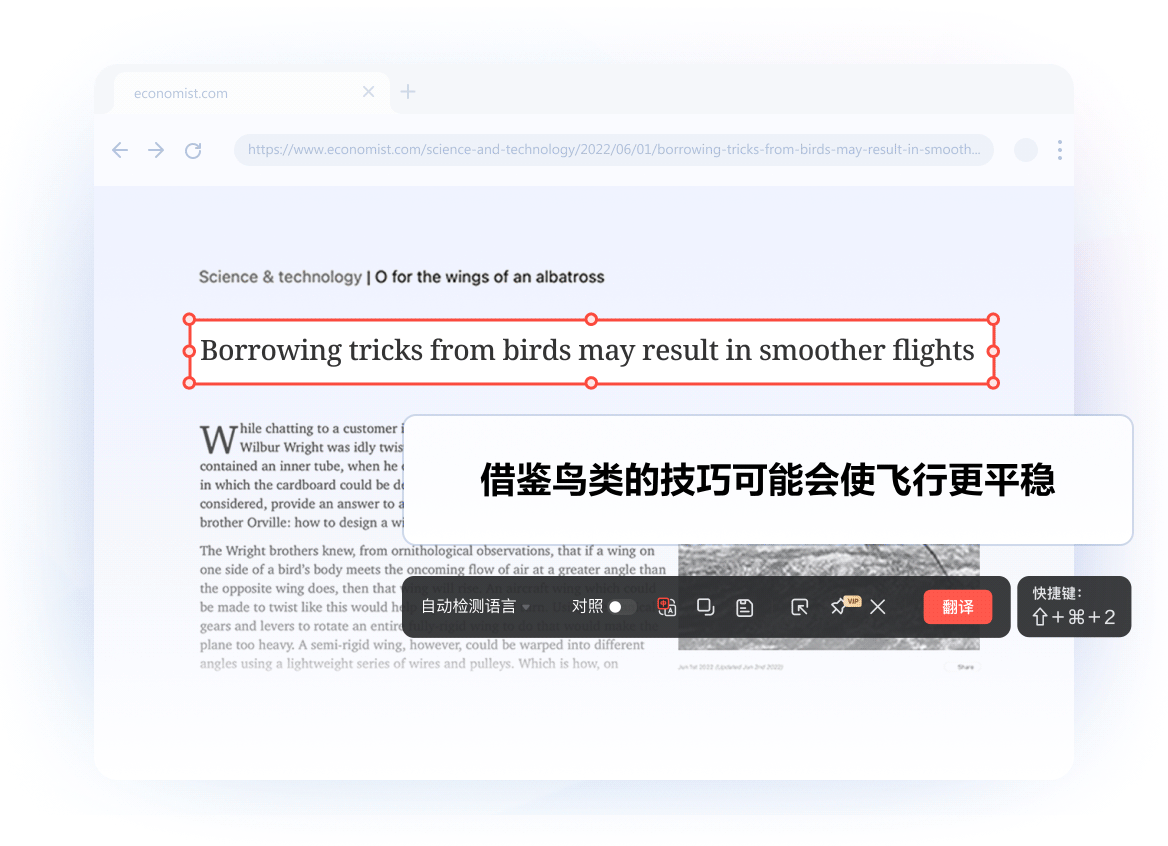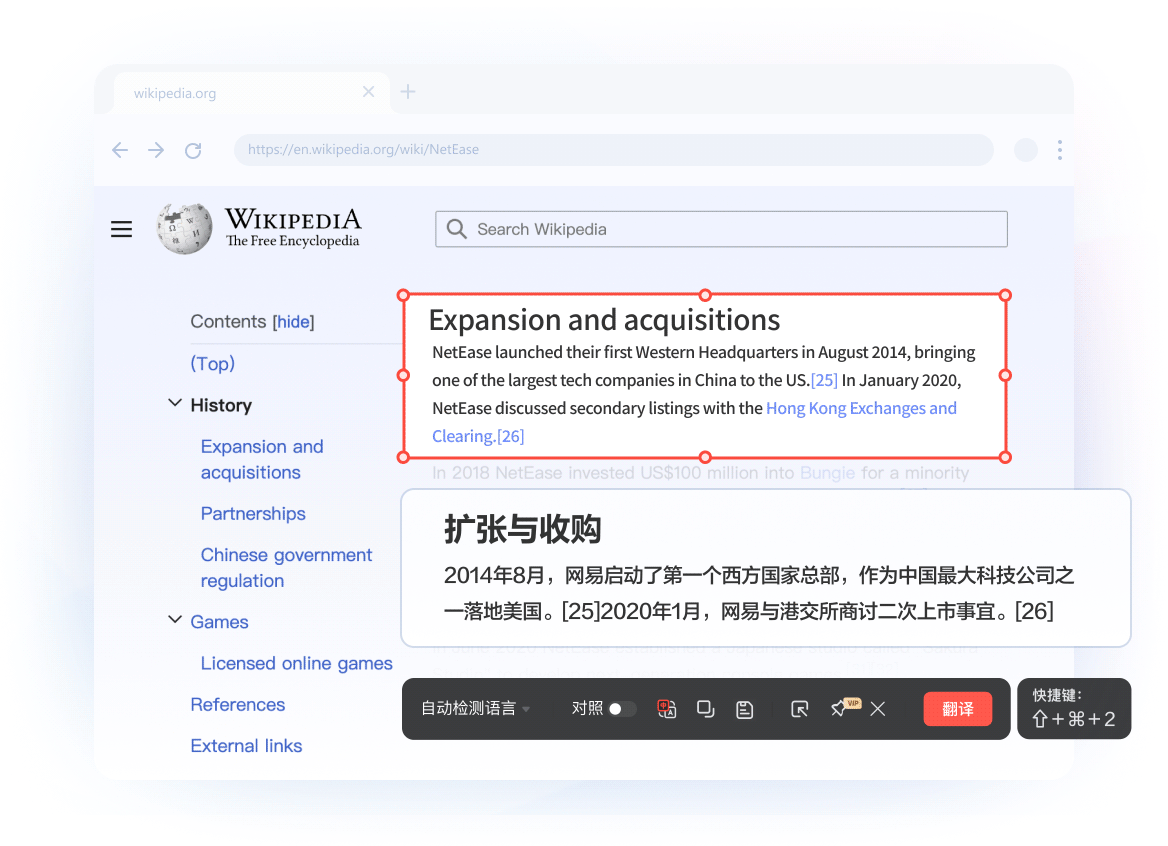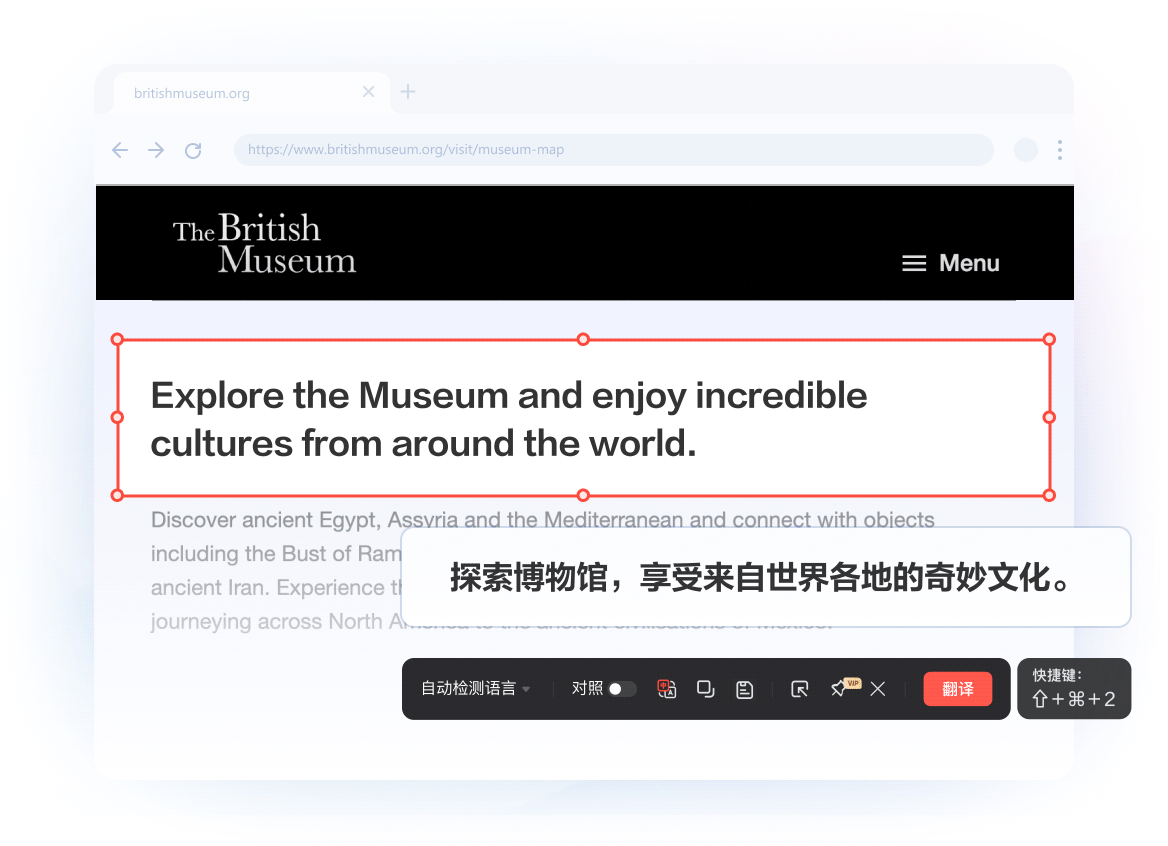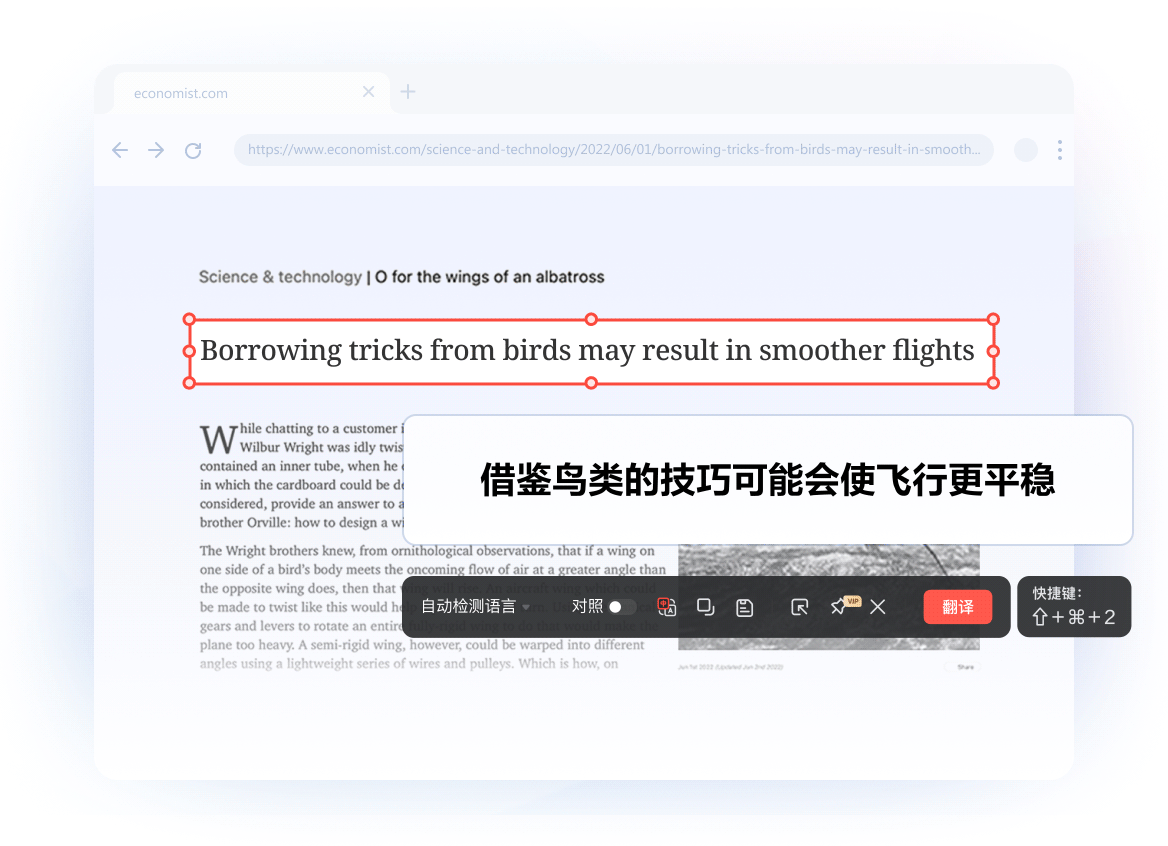
像素级排版复刻: 采用文档结构解析技术,翻译后图表、公式、页眉完美保留,阅读无割裂感。
沉浸式对照视图: 原文与译文左右分屏对照,支持逐段校对与编辑,确保信息零误解。
高额免费权益: 登录即享充足的文档翻译额度,满足日常论文阅读与合同审阅需求。
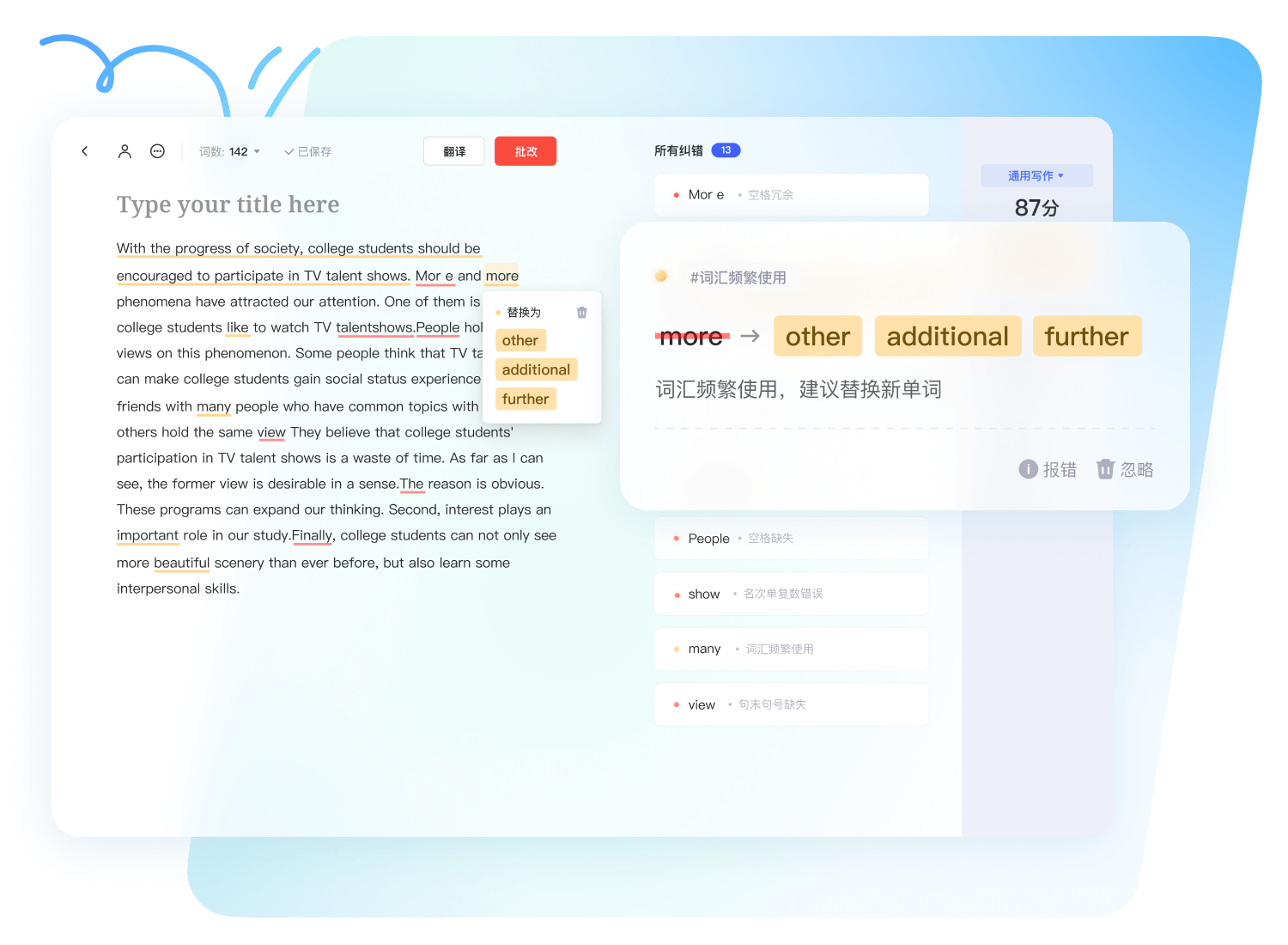
从草稿到定稿,AI 智能审校引擎全程护航内容质量。
针对 SCI 论文投稿与商务邮件场景进行专属模型调优。
一键检索千万级地道双语例句,告别生硬直译。
多维度智能评分,可视化呈现文本提升空间。










要在Linux系统上通过命令行使用有道翻译词典查词,最直接的方法是安装一个基于Python的第三方工具,例如 youdao-dict。您可以通过 pip install youdao-dict-for-ubuntu 命令进行安装,之后在终端输入 yd [要查询的单词或句子] 即可快速获得翻译结果。这种方式无需离开终端界面,能够极大地提升开发者和Linux重度用户的工作效率,实现真正的沉浸式工作流。
2026-03-30展望2026年,有道翻译词典极有可能支持对医学影像报告中缩写的高级翻译。这得益于人工智能技术的飞速发展,特别是大语言模型在上下文理解和专业知识整合方面的突破。虽然届时AI翻译可能仍需专业人士复核以确保100%的临床准确性,但其作为高效的初步解读和辅助理解工具,其价值将变得至关重要,能够极大地提升非专业人士及初级医护人员对复杂医学报告的理解效率。
2026-03-29展望2026年,有道翻译词典极有可能在先进人工智能技术的驱动下,为翻译天文观测指南提供强大的支持。尽管目前在处理高度专业的术语、深层文化背景以及图表等多模态信息方面仍面临挑战,但随着神经网络模型、多模态翻译与知识图谱等技术的飞速发展,实现对天文观测指南这类复杂文本的高质量、高精准度翻译正从愿景走向现实。对于全球的天文爱好者而言,这意味着一个跨越语言障碍的知识共享新时代即将来临。
2026-03-28在有道翻译词典中查看单词的过去式非常直接。您只需在搜索框中输入动词的原形,然后在搜索结果页面的下方查找“词形变换”区域。该区域会清晰地列出单词的过去式 (Past Tense)、过去分词 (Past Participle)、现在分词 (Present Participle)以及第三人称单数 (Third-person Singular)等多种形式。对于不规则动词,有道同样会准确展示其独特的过去式形态。
2026-03-27要在有道翻译词典中查找单词的过去分词,操作非常直接。您只需在搜索框中输入该单词的任意形式(原形、过去式等),点击查询后,在结果页面的“单词形态”或“词形变化”模块中,即可清晰地看到标记为“过去分词 (p p )”的对应词形。这个功能对于英语学习者掌握动词变化至关重要。
2026-03-26关于有道翻译词典的语音翻译功能是否提供多种音色选择,答案是:它主要侧重于提供发音清晰、标准统一的翻译语音,以确保沟通的准确性和高效性。虽然它不像娱乐性应用那样提供儿童、老人或卡通人物等多样化的音色包,但在部分语言的翻译结果中,用户通常可以在标准的男声和女声之间进行切换。该功能的核心优势在于其卓越的翻译准确率、对多种语言及方言的识别能力,而非音色的个性化定制。
2026-03-22UI设计师在查阅Material Design(MD)指南时偏爱使用有道翻译词典,核心原因在于其远超普通翻译软件的专业性和精准度。它不仅能提供设计术语的精确翻译,还能通过丰富的双语例句和权威词典解释,帮助设计师深入理解术语背后的设计理念与上下文,同时,其文档翻译和屏幕划词翻译等功能极大提升了查阅和学习效率,确保了设计语言的统一与准确传达。
2026-03-16护士之所以广泛使用有道翻译词典来备考NCLEX-RN考试,是因为它不仅仅是一个翻译工具,更是一个功能强大的综合性学习平台。它内置了权威的医学词典,能够精准翻译复杂的专业术语;其文档翻译和拍照翻译功能可以高效处理海量的英文教材与题库;独特的单词本和复习系统则帮助护士系统性地攻克词汇难关,从而有效跨越语言障碍,专注于考试内容的学习与理解。
2026-03-15对于艺术生而言,巧妙运用有道翻译词典是成功申请国外艺术院校的关键一步。它不仅能帮助你精准翻译作品集中的复杂艺术概念、通过其强大的AI功能深度润色个人陈述,还能高效处理成绩单等学术文件。这种全方位的语言支持,可以显著提升你全套申请材料的专业度和影响力,助你牢牢抓住招生官的目光。
2026-03-14编剧使用有道翻译词典查询好莱坞剧作格式,主要是因为它不仅能解决语言翻译问题,更能作为专业术语的“活字典”,帮助编剧精准理解和运用格式规范中的特定缩写、动作描述和场景指令。它能快速厘清INT EXT , V O , O S 等术语的含义及用法,并通过海量例句库提供地道的行业语境,从而确保剧本的专业性和可读性,是连接本土创作与国际标准的重要桥梁。
2026-03-13想快速看懂英文气象报告,最有效的方法是利用有道翻译词典的多种功能。您可以通过文本翻译功能输入天气预报中的生僻词汇或完整句子获取即时翻译;使用拍照翻译功能,对准手机App、网页或电视屏幕上的天气信息,即可获得实时翻译,尤其适合处理图文混排的内容。
2026-03-13到2026年,有道翻译不仅极有可能支持翻译咖啡机英文说明书,而且其翻译的精准度和用户体验预计将达到前所未有的高度。得益于人工智能和神经网络机器翻译(NMT)技术的飞速发展,处理包含专业术语和复杂图表的说明书将变得轻而易举,用户只需通过文档翻译或拍照翻译功能,即可快速获取清晰、准确的中文指导。
2026-03-10宠物医生在面对进口兽药时,之所以倾向于使用有道翻译词典,核心原因在于其精准的专业词汇翻译、高效的拍照翻译功能、以及强大的文档整体翻译能力。在分秒必争的诊疗环境中,这些功能组合不仅能快速突破语言障碍,更能确保用药的准确性和安全性,是保障宠物生命健康的重要辅助工具。
2026-03-09在有道翻译词典中查看卡牌效果的英文解释,最快捷的方法是使用拍照翻译功能。您只需打开App,将摄像头对准实体卡牌或屏幕上的卡牌图片,即可实时获取高亮显示的翻译结果,并能方便地对照查看详细的英文原文与释义。对于游戏截图,则可使用图片翻译功能一键导入识别,精准获取卡牌描述。
2026-03-09潜水员之所以选择有道翻译词典来查阅潜水电脑表,核心在于其对专业术语的精准翻译能力、强大的离线使用功能以及便捷的拍照和AR翻译技术。这些功能共同确保了潜水员在面对复杂设备和多语言环境时,能够准确理解关键安全信息,从而保障每一次下潜的安全。
2026-03-08目前,[有道翻译](https: www mac-youdao com)词典的“AR翻译”功能主要致力于实时识别并翻译视野中的文字信息,尚不直接支持识别特定物品型号,例如高尔夫球杆的具体型号。该功能的核心技术是基于光学字符识别(OCR)与神经网络机器翻译(NMT),其设计初衷是帮助用户跨越语言障碍,快速理解菜单、路牌、产品说明等场景下的外语文本,而非进行复杂的物品视觉识别与数据库匹配。
2026-03-08在观看棒球比赛或阅读相关资讯时,您是否经常被各种英文缩写所困扰?其实,利用工具可以轻松解决这个问题。要在有道翻译词典中查找棒球术语英文缩写,最直接的方法是在搜索框中输入您已知的中文术语(如“本垒打”)或英文全称(如“Home Run”),其详细释义页面通常会在专业词汇或网络释义部分提供对应的缩写(如HR)。反之,如果您已知一个缩写(如“RBI”),直接搜索它,词典也会给出其完整的含义“Run Batted In”以及中文解释“打点”。
2026-03-08在有道翻译词典中查看滑板动作的英文名称,最直接的方法是输入已知的中文名称,如“豚跳”或“尖翻”,即可获得对应的英文“Ollie”或“Kickflip”。您还可以利用拍照翻译功能,对准滑板视频或图片中的动作进行实时识别和翻译,或者通过详细描述动作,如“板子纵向旋转”,来辅助查找。
2026-03-07要在有道翻译词典中查看声部划分的英文名称,只需打开有道翻译APP或网站,在输入框中键入中文声部名称,如“女高音”,即可在结果中看到其对应的英文“Soprano”以及详细的释义、发音和例句。有道强大的词库和百科功能还能提供更深入的背景知识,帮助您全面理解各个声部的特点和区别。
2026-03-07欧美圈同人写手偏爱使用有道翻译词典,主要因为它不仅提供精准的单词翻译,更能深入解析英文原著中的文化背景、俚语和复杂语境。其强大的权威例句库、词根词缀分析、网络释义及摄像头取词等功能,能够帮助写手们在阅读原著时精准把握角色语气与情感细节,从而进行忠于原作精神(Canon)且富有创造力的高质量二次创作,是连接深度阅读与精妙表达的得力工具。
2026-03-07在大多数情况下,[有道翻译](https: www mac-youdao com)词典的“AR翻译”功能能够识别并翻译打印耗材(如墨盒、硒鼓)标签上的文字。这项功能通过手机摄像头实时捕捉文字并叠加翻译,非常适合快速理解进口耗材的型号、颜色、兼容性及注意事项等信息。然而,翻译的准确性会受到标签表面反光、字体大小、印刷质量以及光线条件等多种因素的影响。
2026-03-05要在有道翻译词典中查找植物分类学的英文术语,最有效的方法是直接在搜索框中输入植物的中文名、拉丁学名或具体的分类学词汇(如“被子植物”)。为获得更精准的结果,建议利用其内置的“完整释义”功能,深入查看柯林斯词典、专业释义和网络释义,并通过分析双语例句来确认术语在具体语境中的用法。对于科、属、种等核心概念,直接查询其中文,即可得到对应的标准英文翻译。
2026-03-04要快速积累英文文学评论词汇,核心在于利用有道翻译词典的“专业释义”功能精准查词,通过“权威双语例句”理解语境,再借助“单词本”进行系统性复习,并结合“文档翻译”和AI功能进行沉浸式阅读与应用练习,从而实现从认知到掌握的飞跃。这种方法将零散的查词行为转变为一个系统化的学习流程,极大提升了学习效率和词汇应用的准确性。
2026-03-02备考CSCS体能专家认证,核心在于攻克海量专业英语词汇。高效利用有道翻译词典的文档翻译功能整体通读教材,使用拍照翻译功能快速查阅图表词汇,并通过单词本功能建立个人专属的CSCS核心词库,是克服语言障碍、提升学习效率的关键策略。这种方法能够帮助考生将精力更多地集中在理解复杂的体能训练科学原理和应用上,而非在语言壁垒上消耗过多时间。
2026-03-01

关注官方公众号
获取最新产品福利


